
Tìm Hiểu Convolutional Neural Networks Cho Phân Loại Ảnh
Giới Thiệu
Convolutional Neural Networks (CNN) là một trong những mô hình deep learning phổ biến nhất và có ảnh hưởng nhiều nhất trong cộng đồng Computer Vision. CNN được dùng trong trong nhiều bài toán như nhân dạng ảnh, phân tích video, ảnh MRI, hoặc cho bài các bài của lĩnh vự xử lý ngôn ngữ tự nhiên,và hầu hết đều giải quyết tốt các bài toán này.
CNN cũng có lịch sử khá lâu đời. Kiến trúc gốc của mô hình CNN được giới thiệu bởi một nhà khoa học máy tính người Nhật vào năm 1980. Sau đó, năm 1998, Yan LeCun lần đầu huấn luyện mô hình CNN với thuật toán backpropagation cho bài toán nhận dạng chữ viết tay. Tuy nhiên, mãi đến năm 2012, khi một nhà khoa học máy tính người Ukraine Alex Krizhevsky (đệ của Geoffrey Hinton) xây dựng mô hình CNN (AlexNet) và sử dụng GPU để tăng tốc quá trình huấn luyện deep nets để đạt được top 1 trong cuộc thi Computer Vision thường niên ImageNet với độ lỗi phân lớp top 5 giảm hơn 10% so với những mô hình truyền thống trước đó, đã tạo nên làn sóng mãnh mẽ sử dụng deep CNN với sự hỗ trợ của GPU để giải quyết càng nhiều các vấn đề trong Computer Vision.
Image Classification
Trong bài blog này, mình giới thiệu kiến trúc cụ thể của mô hình CNN cho bài toán phân loại ảnh. Phân loại ảnh là một bài toán quan trọng bậc nhất trong lĩnh vực Computer Vision. Chúng ta đã có rất nhiều nghiên cứu để giải quyết bài toán này bằng cách rút trích các đặc trưng rất phổ biến như SIFT, HOG rồi cho máy tính học nhưng những cách này tỏ ra không thực sự hiểu quả. Nhưng ngược lại, đối với con người, chúng ta lại có bản năng tuyệt vời để phân loại được những đối tượng trong khung cảnh xung quanh một cách dễ làm.
Dữ liệu đầu vào của bài toán là một bức ảnh. Một ảnh được biểu ảnh bằng ma trận các giá trị. Mô hình phân lớp sẽ phải dự đoán được lớp của ảnh từ ma trận điểm ảnh này, ví dụ như ảnh đó là con mèo, chó, hay là chim.

Để biểu diễn một bức ảnh 256x256 pixel trong máy tính thì ta cần ma trận sẽ có kính thước 256x256 chiều, và tùy thuộc vào bức ảnh là có màu hay ảnh xám thì ma trận này sẽ có số kênh tương ứng, ví dụ với ảnh màu 256x256 RGB, chúng ta sẽ có ma trận 256x256x3 để biểu diễn ảnh này.
Mối liên kết giữ CNN và thị giác
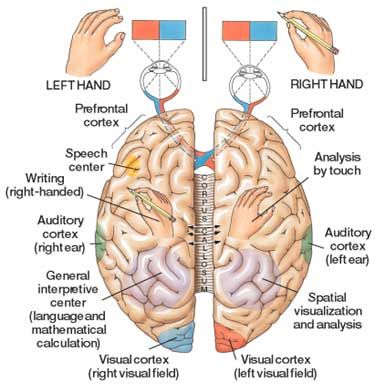
CNN có mối liên kết chặt chẽ với sinh học, cụ thể là của võ não thị giác, nơi xử lý thông tin liên quan đến hình ảnh từ các tế bào cảm thụ ánh sánh nằm ở mắt người. Năm 1962, 2 nhà thần kinh học người Mỹ là Hubel and Wiesel đã thực hiện thí nghiệm khám phá cách tổ chức của các tế bào não để xử lý thông tin thị giác và các tổ chức này đảm nhận nhiệm vụ nào. Trong video này, các bạn có thể nghe được âm thanh đại diện cho các tế nào não phản ứng lại với các hình ảnh, góc cạnh, hướng của các đường thẳng xuất hiện trong video theo một trật tự nhất định. Điều này có nghĩ là mỗi neuron được thiết lập để phản ứng lại một số đặc điểm cố định của neuron đó.
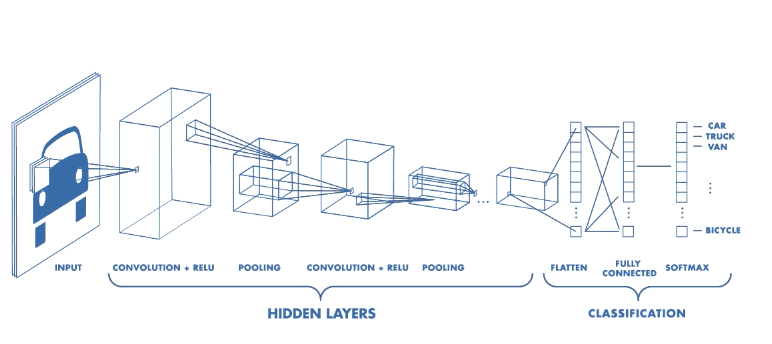
Cấu trúc CNN
CNN bao gồm tập hợp các lớp cơ bản bao gồm: convolution layer + nonlinear layer, pooling layer, fully connected layer. Các lớp này liên kết với nhau theo một thứ tự nhất định. Thông thường, một ảnh sẽ được lan truyền qua tầng convolution layer + nonlinear layer đầu tiên, sau đó các giá trị tính toán được sẽ lan truyền qua pooling layer, bộ ba convolution layer + nonlinear layer + pooling layer có thể được lặp lại nhiều lần trong network. Và sau đó được lan truyền qua tầng fully connected layer và softmax để tính sác xuất ảnh đó chứa vật thế gì.
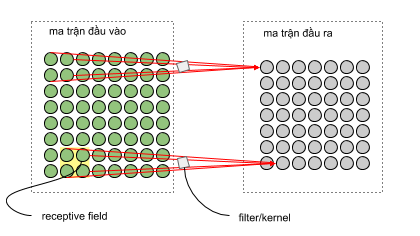
Convolution Layer
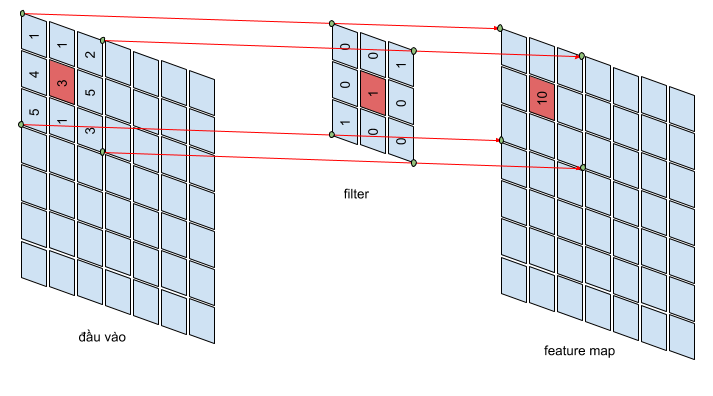
Convolution layer là lớp quan trọng nhất và cũng là lớp đầu tiên của của mô hình CNN. Lớp này có chức năng chính là phát hiện các đặc trưng có tính không gian hiệu quả. Trong tầng này có 4 đối tượng chính là: ma trận đầu vào, bộ filters, và receptive field, feature map. Conv layer nhận đầu vào là một ma trận 3 chiều và một bộ filters cần phải học. Bộ filters này sẽ trượt qua từng vị trí trên bức ảnh để tính tích chập (convolution) giữa bộ filter và phần tương ứng trên bức ảnh. Phần tưng ứng này trên bức ảnh gọi là receptive field, tức là vùng mà một neuron có thể nhìn thấy để đưa ra quyết định, và mà trận cho ra bới quá trình này được gọi là feature map. Để hình dung, các bạn có thể tưởng tượng, bộ filters giống như các tháp canh trong nhà tù quét lần lượt qua không gian xung quanh để tìm kiếm tên tù nhân bỏ trốn. Khi phát hiện tên tù nhân bỏ trốn, thì chuông báo động sẽ reo lên, giống như các bộ filters tìm kiếm được đặc trưng nhất định thì tích chập đó sẽ cho giá trị lớn.

Với ví dụ ở bên dưới, dữ liệu đầu vào ở là ma trận có kích thước 8x8x1, một bộ filter có kích thước 2x2x1, feature map có kích thước 7x7x1. Mỗi giá trị ở feature map được tính bằng tổng của tích các phần tử tương ứng của bộ filter 2x2x1 với receptive field trên ảnh. Và để tính tất cả các giá trị cho feature map, các bạn cần trượt filter từ trái sáng phải, từ trên xuống dưới. Do đó, các bạn có thể thấy rằng phép convolution bảo toàn thứ tự không gian của các điểm ảnh. ví dụ điểm góc gái của dữ liệu đầu vào sẽ tương ứng với bên một điểm bên góc trái của feature map.
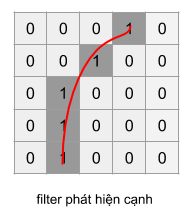
Tầng convolution như là feature detector
Tầng convolution có chức năng chính là phát hiện đặc trưng cụ thể của bức ảnh. Những đặc trưng này bao gồm đặc trưng cơ bản là góc,cạnh, màu sắc, hoặc đặc trưng phức tạp hơn như texture của ảnh. Vì bộ filter quét qua toàn bộ bức ảnh, nên những đặc trưng này có thể nằm ở vị trí bất kì trong bức ảnh, cho dù ảnh bị xoáy trái/phải thì những đặc trưng này vẫn bị phát hiện.
Ở minh họa dưới, các bạn có một filter 5x5 dùng để phát hiện góc/cạnh với, filter này chỉ có giá trị một tại các điểm tương ứng một góc cong.
Dùng filter ở trên trược qua ảnh của nhân vật Olaf trong trong bộ phim Frozen. Chúng ta thấy rằng, chỉ ở những vị trí trên bức ảnh có dạng góc như đặc trưng ở filter thì mới có giá trị lớn trên feature map, những vị trí còn lại sẽ cho giá trị thấp hơn. Điều này có nghĩa là, filter đã phát hiện thành công một dạng góc/cạnh trên dự liệu đầu vào. Tập hơn nhiều bộ filters sẽ cho phép các bạn phát hiện được nhiều loại đặc trưng khác nhau,và giúp định danh được đối tượng.

Các tham số của tầng convolution: Kích thước bộ filter, stride và padding
Kích thước bộ filter là một trong những tham số quan trọng nhất của tầng convolution. Kích thước này tỉ lệ thuận với số tham số cần học tại mỗi tầng convolution và là tham số quyết định receptive field của tầng này. Kích thước phổ biến nhất của bộ filter là 3x3.
Kích thước filter nhỏ được ưu tiên lựa chọn thay kích thước lớn vì những lý do sau đây.
| Filter Nhỏ | Filter Lớn |
|---|---|
| Kích thước nhỏ thì mỗi lần nhìn được một vùng nhỏ các pixel | Receptive field lớn |
| Rút trích được đặc trưng có tính cục bộ cao | Các đặc trưng có tính tổng quát hơn |
| Phát hiện được các đặc trưng nhỏ hơn | Bắt được những phần cơ bản của bức ảnh |
| Đặc trưng rút trích được sẽ đa dạng, hữu ích hơn ở tầng sau | Thông ít rút trích được ít đa dạng |
| Giảm kích thước ảnh chậm hơn, do đó cho phép mạng sâu hơn | Giảm kích thước ảnh nhanh, do đó chỉ cho phép mạng nông |
| Ít trọng số hơn, chia sẻ trọng số tốt hơn | Chia sẽ trọng số ít ý nghĩa hơn |
Kích thước filter của tầng convolution hầu hết đều là số lẻ, ví dụ như 3x3 hay 5x5. Với kích thước filter lẻ, các giá trị của feature map sẽ xác định một tâm điểm ở tầng phía trước. Nếu các bạn chọn filter có kích thước 2x2, 4x4 thì chúng ta sẽ gặp khó khăn khi muốn tìm vị trí tương ứng của các giá trị feature map trên không gian ảnh.
Ở những trường hợp đặt biệt như filter có kích thước 1x1, hay có kích thước bằng với ma trận đầu vào, tầng convolution có ý nghĩa rất thú vị. Khi có kích thước 1x1, tầng convolution xem mỗi điểm như một đặc trưng riêng biệt, có chức năng giảm chiều (tăng chiều) khi số lượt feature map ở tầng sau nhỏ hơn (lớn hơn) tầng trước. Filter 1x1 đã được sử dụng trong kiến trúc mạng phổ biến như Inception networks. Trong khi đó, filter với kích thước bằng ảnh đầu vào, tầng convolution có chức năng y hệt fully connected layer.
Ngoài ra, các bạn cần lưu ý tham số stride, thể hiện số pixel bạn cần phải dịch chuyển mỗi khi trượt bộ filter qua bức ảnh. Ở ví dụ bên dưới, với tham số stride bằng 2, bộ filter sẽ dịch chuyển 2 pixel mỗi lần áp dụng phép convolution.
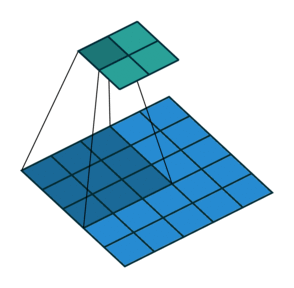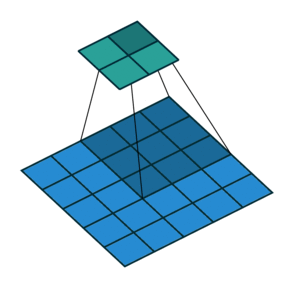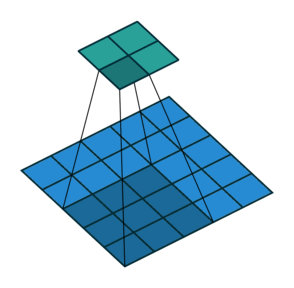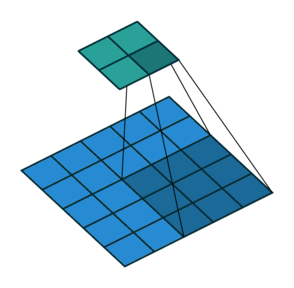
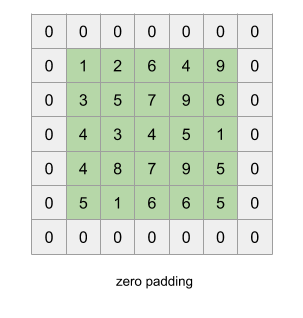
Khi các bạn áp dụng phép convolution thì ma trận đầu vào sẽ có nhỏ dần đi, do đó số layer của mô hình CNN sẽ bị giới hạn, và không thể xậy đựng deep nets mong muốn. Để giải quyết tình trạng này, các bạn cần padding vào ma trận đầu vào để đảm bảo kích thước đầu ra sau mỗi tầng convolution là không đổi. Do đó có thể xậy dựng được mô hình với số tầng convolution lớn tùy ý. Một cách đơn giản và phổ biến nhất để padding là sử dụng hàng số 0, ngoài ra các bạn cũng có thể sử dụng reflection padding hay là symmetric padding.
Nonlinear Layer
ReLU (Rectified Linear Units, f = max(0, x)) là hàm kích hoạt phổ biến nhất cho CNN tại thời điểm của bài viết, được giới thiệu bởi Geoffrey E. Hinton năm 2010. Trước khi hàm ReLU được áp dụng thì những hàm như sigmoid hay tanh mới là những hàm được sử dụng phổ biến. Hàm ReLU được ưa chuộng vì tính toán đơn giản, giúp hạn chế tình trạng vanishing gradient, và cũng cho kết quả tốt hơn. ReLU cũng như những hàm kích hoạt khác, được đặt ngay sau tầng convolution, ReLU sẽ gán những giá trị âm bằng 0 và giữ nguyên giá trị của đầu vào khi lớn hơn 0.
ReLU cũng có một số vấn đề tiềm ẩn như không có đạo hàm tại điểm 0, giá trị của hàm ReLU có thể lớn đến vô cùng và nếu chúng ta không khởi tạo trọng số cẩn thận, hoặc khởi tạo learning rate quá lớn thì những neuron ở tầng này sẽ rơi vào trạng thái chết, tức là luôn có giá trị < 0.
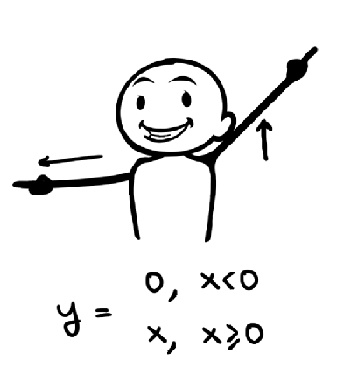
Pooling Layer
Sau hàm kích hoạt, thông thường chúng ta sử dụng tầng pooling. Một số loại pooling layer phổ biến như là max-pooling, average pooling, với chức năng chính là giảm chiều của tầng trước đó. Với một pooling có kích thước 2x2, các bạn cần phải trược filter 2x2 này trên những vùng ảnh có kích thước tương tự rồi sau đó tính max, hay average cho vùng ảnh đó.
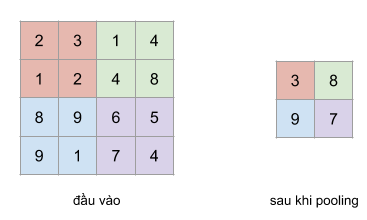
Ý tương đằng sau tầng pooling là vị trí tuyết đối của những đặc trưng trong không gian ảnh không còn cần cần thiết, thay vào đó vị trí tương đối giữ các đặc trưng đã đủ để phân loại đối tượng. Hơn giảm tầng pooling có khả năng giảm chiều cực kì nhiều, làm hạn chế overfit, và giảm thời gian huấn luyện tốt.
Fully Connected Layer
Tầng cuối cùng của mô hình CNN trong bài toán phân loại ảnh là tầng fully connected layer. Tầng này có chức năng chuyển ma trận đặc trưng ở tầng trước thành vector chứa xác suất của các đối tượng cần được dự đoán. Ví dụ, trong bài toán phân loại số viết tay MNIST có 10 lớp tương ứng 10 số từ 0-1, tầng fully connected layer sẽ chuyển ma trận đặc trưng của tầng trước thành vector có 10 chiều thể hiện xác suất của 10 lớp tương ứng.
Và cuối cùng, quá trình huấn luyện mô hình CNN cho bài toán phân loại ảnh cũng tương tự như huấn luyện các mô hình khác. Chúng ta cần có hàm độ lỗi để tính sai số giữ dự đoán của mô hình và nhãn chính xác, cũng như sử dụng thuật toán backpropagation cho quá trình cập nhật trọng số.
Source code
Mình cung cấp file notebook cho các bạn mới bắt đầu tìm hiểu và tập huấn luyện mô hình CNN cho bài toán phân loại ảnh. File này chứa hướng dẫn về mô hình CNN cũng như cách sử dụng tensorflow eager execution để xây dựng model cho dữ liệu ZaloAI Landmark
Các bạn hãy tải về tại đây nhé.