
Data Science là gì. Làm gì để trở thành Data Scientist?
Giới Thiệu
Sau nhiều năm đi làm dưới danh nghĩa là một Data Scientist, mình nhận thấy rằng một bài viết chia sẻ của một người làm trong ngành này sẽ giúp ích cho một số bạn mới ban đầu theo đuổi công việc Data Scientist cho một công ty lớn như FPT, VNG, Tiki sẽ hình dung được một bức ảnh toàn cảnh về công việc khi các bạn bước vào làm. Những chia sẻ này làm những cảm nhận chủ quan nên có thể đúng với người này và cũng có thể sai với những người khác.
Cụ thể hơn trong bài viết này, mình sẽ chia sẻ về sự khác nhau giữa 3 công việc rất gần gũi với nhau như Data Engineer, Data Analytics và Data Scientist khác nhau chỗ nào? Các kiến thức cần có để trở thành Data Scientist, và cuối cùng là các lưu ý và quy tắc khi các bạn bắt đầu một dự án data science cho công ty.
Sự khác biệt giữa Data Engineer, Data Analyst, Data Scientist
Data Engineer là gì?
Data Engineer là những người đảm nhận nhiệm vụ xây dựng hệ thống để lưu trữ và truy xuất dữ liệu của việc kinh doanh của công ty. Là người được tuyển dụng sớm nhất trong 3 công việc trên. Bên cạnh việc chính là lưu trữ và truy xuất, Data Engineer còn phải tối ưu hoá việc lưu trữ để truy vấn nhanh nhất. Ngoài ra, tuỳ thuộc vào bài toán mà hệ thống này phải lưu trữ tính toán realtime. Hệ thống của Data Engineer xây dựng có thể đơn giản hay cực kì phức tạp để phục vụ lương lớn khách hàng, và tất nhiên tuỳ thuộc vào hệ thống phức tạp hay không mà yêu cầu về kinh nghiệm và trình độ của người Data Engineer cũng khác nhau. Thông thường, Data Scientist hay Data Analyst đều phải làm việc với Data Engineer để tìm hiểu về hệ thống hiện tại, nắm được bức tranh tổng quát về luồng dữ liệu trong hệ thống từ đó giúp cho các bạn hiểu được data sẽ có khi nào và nơi nào lưu trữ và ý nghĩa chung của những loại dữ liệu.
Những tool mà mình biết các bạn Data Engineer thường xuyên làm việc là các tool liên quan đến lưu trữ dữ liệu như Mongo, SQL, Postgres, những công cụ như Spark giúp xây dựng một hệ thống phân tán. Ngôn ngữ mà Data Engineer thường dùng là Java.
Data Analyst là ai?
Sau khi dữ liệu được lưu trữ, lúc này các công cty sẽ có nhu cầu phân tích dữ liệu để biết được tình trạng hiện tại của việc kinh doanh. Lúc đó một Data Analytics sẽ được tuyển dụng và làm những công việc như đưa ra các số liệu thống kê, theo dõi các chỉ số về tình trạng hoạt động của công cty. Một Data Analytics như làm dâu trăm họ. Các team khác nhau của công ty đều cần tới để lấy chỉ số, để yêu cầu các report, để hỗ trợ đo đếm số liệu cho một tính năng mới. Cuộc sống của một data analyst thường xoay quanh report.
Các data analyst cần có những kiến thức cơ bản về xác suất và thống kê để tránh đưa ra những báo cáo bị bias. Điều này là cực kì quan trọng vì data analyst cũng chính là người đưa ra những lời khuyên cho bên kinh doanh. Do đó các kết luận không chính xác đều gây ra những ảnh hưởng tiêu cực.
Các ngôn ngữ lập trình mà data analyst hay sử dụng là Python, R, hay thậm chí là Excel. Do đó, nếu bạn mong muốn làm data analyst thì hãy thật vững 2 ngôn ngữ lập trình này.
Hình dưới mình ghi lại những từ khoá quan trọng mà các bạn khi muốn trở thành data analyst thì cần phải biết và nắm thật vững nhé. Có khá nhiều bạn muốn trở thành data analyst và có chuyên môn bên kinh tế nên những điều này hy vọng sẽ vạch ra con đường rõ ràng hơn cho các bạn đi tiếp.
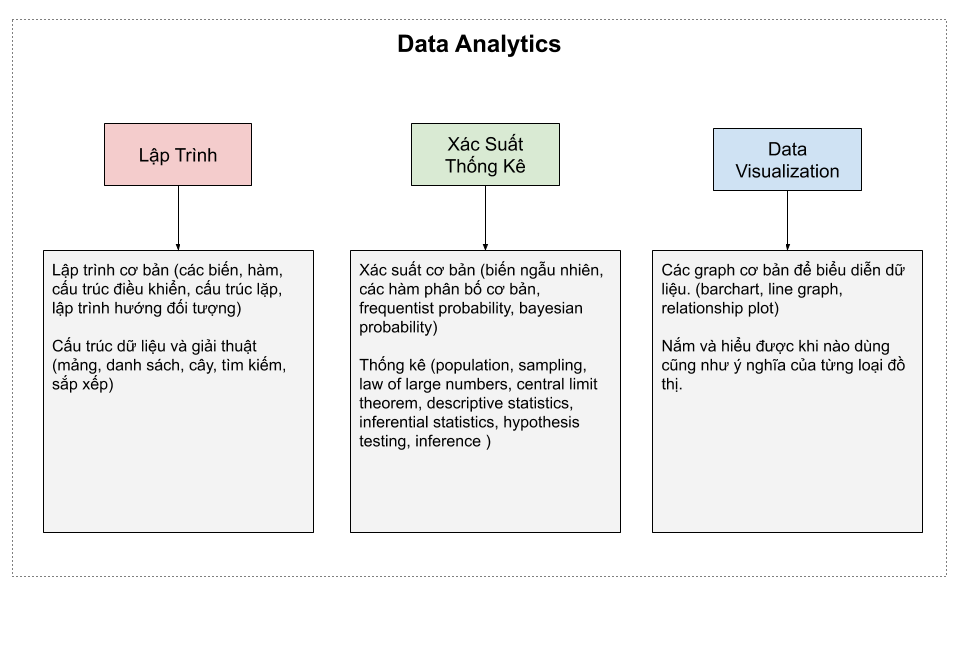
Các kiến thức cơ bản cần có để trở thành Data Scientist
Người ta hay bảo nhau rằng Data Scientist: The Sexiest Job of the 21st Century. Tuy nhiên, những năm vừa qua do việc tuyển dụng khá nhiều nên title Data Scientist đôi khi được đặt lên nhầm người. Bản thân mình cũng thấy cái tên gọi Data Scientist cũng là chưa thực sự phù hợp với khả năng hiện tại.

Để trở thành Data Scientist các bạn phải có nhiều kiến thức cũng như là kinh nghiệm (những bài học từ những sai lầm) trong quá trình làm việc. Các kiến thức đó bao gồm: Ngôn ngữ lập trình, Cơ sở dữ liệu và tính toán phân tán, Software/Web Engineering, Data Visualization and storyteller, Data Sense, Xác suất và thống kê, Máy học, Deep Learning, Giải tích và đại số tuyến tính. Những kiến thức trên hầu hết đều được mình sử dụng trong để giải quyết cho những bài toán hiện tại, cho nên kiến thức trên đều quan trọng chứ không phải chỉ là một đống lý thuyết chỉ liệt kê trên giấy.
Ngôn ngữ lập trình ở đây là các kiến thức về lập trình như các cơ bản của một ngôn ngữ, cấu trúc dữ liệu, lập trình hướng đối tượng. Những kiến thức này chính là nền tảng của mọi lập trình viên. Do đó sẽ giúp ích rất nhiều cho khi làm việc thực tế để hiểu,viết và tổ chức mã nguồn cho hợp lý, gọn gàng và dễ phát triển về sau.
Cơ sở dữ liệu và tính toán phân tán là kiến thức về các cơ sở dữ liệu phổ biến như mysql, mongo, redis, mapreduce concept, hadoop, spark, cách tổ chức và xây dựng hệ thống để hỗ trợ việc xây dựng mô hình máy học có thể scale khi cần thiết và chạy được cả offline và online để đưa ra các dự đoán nhanh chóng.
Với những kiến thức cơ bản về web programming, các Data Scientist có thể tự tạo một dashboard cơ bản để theo dõi kết quả của mô hình, các chỉ số liên quan để đánh giá ảnh hưởng của dự án đến người dùng, hoặc là một giao diện đơn giản để a/b testing, hoặc là dùng để labeling hay đơn giản là để thể hiện kết quả ra bên ngoài cho nội bộ team sài và đánh giá. Việc tạo ra một giao diện có tương tác sẽ giúp ích và giảm thiểu thời gian đánh giá kết quả đi rất nhiều. Với những team nhỏ, không có đủ nhân lực thì kiến thức về lập trình web sẽ rất hữu ý cho một Data Scientist.
Data Visualization là kĩ năng dùng đồ thị để minh hoạ cho những con số, các Data Scientist cần biết những đồ thị nào là phù hợp để minh hoạ cho những insight của dữ liệu, minh hoạ các con số được nói từ dữ liệu. Ngoài ra có thể tự tạo được những đồ thị phù hợp với ý muốn của mình. Song song bên cạnh Data Visualization là kỹ năng storytelling, kỹ năng này giúp Data Scientist truyền tải những con số , những insight từ mô hình máy học thành những lời nói dễ hiểu cho những bên liên quan, đặt biệt là bên kinh doanh, hoặc cấp trên. Kỹ năng này liên quan tới vấn đề giao tiếp nhiều hơn.
Data Sense thực chất là những cảm nhận hay trực giác khi giải quyết bài toán. Khả năng này khá mơ hồ và cũng rất thú vị. Khả này này giúp chúng ta đạt ra những câu hỏi nghi ngờ hay tìm hướng đi đúng đắn cho bài toán. Vì mỗi mô hình kinh doanh lại có những vấn đề cụ thể khác nhau. Thông thường khi giải quyết bài toán, chúng ta không đơn giản chỉ là dùng một máy học phổ biến như XGBoost, hay là logistics regression là xong. Mà phải biết cách thiết kế luồng đi của của việc dự đoán phù hợp với nhu cầu của mọi người.
Xác suất và thống kê là kiến thức không thể thiếu đối với một Data Scientist thực sự. Cũng giống như Data Analytics, các kiến này bao gồm: biến ngẫu nhiên, các hàm phân bố cơ bản, frequentist probability, bayesian probability, population, sampling, law of large numbers, central limit theorem, hypothesis testing, bayesian inference. Các kiến thức này cực kì hữu dụng cho các Data Scientist hiểu kĩ hơn về dữ liệu. Giúp mình xây dựng những mô hình thống kê để giải quyết bài toán.
Machine learning (Máy học) thì không cần phải bàn nhiều vì nó chính là kiến thức trọng tâm của một Data Scientist, là công cụ để giải quyết hầu hết các bài toán. Hiểu được ưu nhược điểm của mô hình máy học giúp cho mình tự tin và lựa chọn được một mô hình phù hợp. Mô hình máy học thì mênh mông. Tuy nhiên, các mô hình được sài thường xuyên là logistic regression, Decision tree, Gradient Boosted Machine. Các bạn hãy nắm thật vựng về nó nhé.
Deep Learning là kiến thức cũng không thể thiếu được của một Data Scientist. Những mô hình này giải quyết tốt các bài toán liên quan đến hình ảnh và ngôn ngữ tự nhiên. Hiện tại, Deep Learning vẫn là một topic hot nhất và sôi động nhất trong giới học thuật và được ứng dụng khá nhiều trong đời sống. Các bạn ắt hẳn đã từng nghe về hệ thống nhận dạng khuôn mặt của Trung Quốc, tạo ra các bản nhạc, rồi tới chơi cờ vây. Các mô hình chủ yếu là Convolution Neural Nets và Recurrent Neural Nets. Các biến dạng của 2 mô hình này thì có vô vàng. Các bạn hãy tận dụng thành xuân mà học cho hết nhé.
Giải tích và đại số tuyến tính là kiến thức toán nền toán của các mô hình máy học. Giúp các bạn nắm vững phần toán sau những mô hình đó, từ đó giúp các bạn khả năng đọc hiểu được các tài liệu học thuật để cập nhật các kiến thức, mô hình máy học mới nhất.
Chu trình của một project data science
Tìm hiểu về business
Đây là bước đầu tiên trong một dự án data science bất kỳ. và do đó, cũng là bước quan trọng nhất của toàn bộ dự án. Hiểu được ngữ cảnh của vấn đề kinh doanh cần được trợ giúp từ góc nhìn của data science sẽ giúp các bạn xác định rõ ràng mục tiêu cần được tối ưu dưới góc nhìn của một mô hình máy học. Trong bước này, chúng ta cần có thật nhiều kiến thức và kinh nghiệm trong vấn đề của kinh doanh. Từ đó, giúp chúng ta có những ý tưởng tốt trong bước feature engineering. Tuy nhiên, thông thường với nền tảng là một lập trình viên, chúng ta thường thiếu các kiến thức này, do đó, mình gợi ý các bạn hãy làm việc trực tiếp với bên kinh doanh, cố gắng hiểu thật kĩ những vấn đề của họ trước ghi các bạn thực hiện các bước tiếp theo.
Mình muốn nhấn mạnh một lần nữa, có cái nhìn cụ thể, rõ ràng về vấn đề kinh doanh là rất quan trọng cho toàn bộ dự án. Giúp các bạn định hướng rõ ràng mục tiêu của dự án,các KPI và đảm bảo những gì bạn làm ra đem lại giá trị cho các bộ phận liên quan.
Data collection
Giai đoạn này liên quan đến quá trình kiến thức của Data engineering. Data dùng cho một dự án data science có thể đến từ nhiều nguồn khác nhau, ví dụ như đến từ các file csv, json, hoặc là từ cơ sở dữ liệu lớn. Do đó kiến thức về ETL dữ liệu và SQL sẽ giúp ích khá nhiều trong giai đoạn này. Trong một số trường hợp, dữ liệu có thể không có sẵn mà các bạn phải tự thu thập trên các website. Một ít kiến thức về html cũng như về web api sẽ rất là hữu ích để giúp các bạn giải quyết khó khăn này. Một thư viện python mà mình hay sài để thu thập dữ liệu từ các website là beautifulsoup, các bạn cũng có thể tìm hiểu nhé.
Data Cleaning
Dữ liệu mà các bạn thu thập ở bước trên thông thường chưa được sử dụng ngay để đưa vào các mô hình máy học do chưa nhiều nhiễu hay các biến kiểu categorical hay các giá trị bị rỗng. Do đó, các bạn cần phải xử lý các dữ liệu như vậy trước thực hiện những bước tiếp theo. Một số vấn đề phổ biến trong giai đoạn xử lý dữ liệu này là thay thế các giá trị rỗng bằng một giá trị mặc định như trung bình, hay bất kì giá trị nào có ý nghĩa theo trong ngữ cảnh của bài toán. Các biến kiểu categorical thường được mã hoá sang vector dạng one-hot hoặc những vector biểu diễn khác được học từ các mô hình deep learning. Các outlier cần được xem xét và nên được xoá khỏi dữ liệu. Xác định các outlier này thường phụ thuộc vào kiến thức của lĩnh vực kinh doanh thực tế.
Các bạn hãy luôn nhớ rằng việc làm sạch dữ liệu là việc cực kì quan trọng. Để bảo đảm mô hình có thế hội tụ cũng như trách các kết quả bất thường khi dự đoán.
Exploration Data Analysis
Đã có dữ liệu rồi bước tiếp theo các bạn cần là tìm hiểu dữ liệu bằng một số chỉ số thống kê cơ bản, và các kĩ thuật visualization để nhìn tận mắt vào những đối tượng các bạn cần làm việc. Thông thường, các bạn cần xem xét phân bố các của biến, mối tương quan giữa các biến với nhau và với biến cần dự đoán. Kiểm tra xem các lớp cần dự đoán có cân bằng hay không hay thậm chí thực hiện một số hypothesis test. Hoặc dimension reduction để xem phân bố trên không gian 2 hay 3 chiều như thế nào, có tuyến tính hay không hay là ngẫu nhiên.
Quá trình tìm hiểu ở trên giúp các bạn đưa ra các nhận định về dữ liệu từ đó có những ý tưởng về việc feature engineering ở bước tiếp theo. Hoặc chọn mô hình hợp lý cho dữ liệu của mình.
Modeling
Trong giai đoạn có thể là phần thú vị nhất đối với hầu hết các bạn. Khi chúng ta cần lựa chọn mô hình để huấn luyện từ tập dữ liệu ở trên, cũng như sử dụng một số kĩ thuật đơn giản như grid search để tunning các tham số của mô hình. Trong hầu hết các trường hợp các bạn có thể sử mô hình đơn giản như linear regression/logistic regression cho việc xây dựng mô hình dự đoán vì 2 mô hình này chạy nhanh cũng như dễ dàng giải thích được kết quả đầu ra. Ngoài ra các cũng nên thử với mô hình gradient boosted machine được cài đặt trong 2 thư việc xgb và lightgbm, 2 mô hình thường cho kết quả tốt nhất đối với các dữ liệu kiểu có cấu trúc.
Khi xây dựng mô hình, các bạn cần lưu ý đến độ trễ của việc dự đoán, tính giải thích được của mô hình. Trong một số trường hợp cần mô hình có thể dự đoán nhanh chóng và cần hiểu được lý do tại sao mô hình lại cho kết quả như vậy, các bạn có thể xem xét sử dụng linear/logistic regression. Ngoài ra, các bạn cần lưu ý rằng, khi sử dụng mô hình linear/logistic regression để dự đoán có độ chính xác 90% thì các bạn không cần thiết phải sử dụng những mô hình phức tạp hơn như neural nets để để cải thiện kết quả lên 1% vì tốn kém về mặc thời gian cũng như 1% cải thiện trong bài toán thức tế có thể không thật sự cần thiết để đánh đổi với tính giải thích được của các mô hình đơn giản.
Performance Evaluation
Huấn luyện xong mô hình thì tất nhiên các bạn cần phải đánh giá và so sánh kết quả với các chỉ số về kinh doanh nếu được. hoặc đơn giản là xem xét các độ đô đơn giản như precision, recall, hoặc cụ thể hơn là confusion matrix, hay các chỉ số như mse. Từ đó, các bạn cần quyết định xem mình nên tiếp tục cải thiện, hay đã đủ tốt để đưa vào production.
Communicating to stakeholders
Ở bước này các bạn cần nói chuyện với bên kinh doanh để trao đổi với họ về những insight của mô hình. Và bên kinh doanh sẽ để xuất các cách để đánh giá mô hình của các bạn bằng các chỉ số của họ. Các bạn cần thuyết phục họ tại sao có thể sử dụng mô hình này để cải thiện hiệu quả công việc mà phương pháp cũ không làm được.
Hãy thuyết phục và kiên trì.
Deployment
Đến bước này các bạn cần làm việc trực tiếp với team data engineer, để triển khai kết quả lên môi trường production. Các bạn cũng có thể cần phải xây dựng một giao diện đơn giản để phục vụ cho các cá nhân sử dụng kết quả của bạn hiệu quả hơn. Ngoài ra, các bạn cũng có thể phải viết lại phần dự đoán bằng ngôn ngữ C/C++ để giảm thời gian dự đoán trong các bài toán cần xử lý lượng lớn dữ liệu.
Real world testing
Kết quả đưa lên production và đánh giá mức độ hiệu quả. Nếu mô hình bạn đem lại kết quả tốt thì xin chúc mừng bạn đã có một dự án thành công. Trong giai đoạn này, các bạn có thể sử dụng A/B test để đánh giá tính hiệu quả khi triển khai mô hình mới mà giúp các bạn đạt được KPI của bên kinh doanh đạt ra.
Operations & Optimization
Ở bước cuối này, khi mô hình đã đưa vào vận hành các bạn cần theo dõi kết quả dự đoán, cũng như tính hiệu quả của mô hình vì trong một số trường hợp thực chưa lường trước như thay đổi phân bố dữ liệu hoặc các yếu tố vận hành sẽ làm cho mô hình các bạn cho kết quả tệ.
Các lưu ý khi bắt đầu một dự án Data Science
Khi bắt đầu các dự án data science, việc các bạn nhận thức được các vấn đề sau sẽ giúp ích rất lớn trong quá trình làm việc và triển khai một dự án thành công. Phần này mình trình bày các rules mà mình thấy quan trọng trong quá trình làm việc. Các bạn nên xem tất cả 43 rules được khuyến nghị bởi Martin Zinkevich tại google để có cái nhìn tổng quan hơn nhé.
Trong hầu hết các trường hợp trong thực tế để có một mô hình machine learning tốt, chúng ta cần phải tập trung vào việc tìm kiếm các features tốt, hơn là đi tìm một mô hình phức tạp như neural nets. Do đó, để xây dựng một mô hình machine learning thành công, các bạn trước hết cần phải xây dựng một pipeline hoàn chỉnh để dễ dàng theo dõi, đánh giá mô hình, dễ dàng thêm features. Từ đó giúp các bạn có thể nhanh chóng thực hiện các thí nghiệm mới. và giúp đồng nghiệp cùng cộng tác với nhau dễ dàng.
Do đó các bạn cần ý thức được những điều sau đây.
- Cần tạo một pipeline hoàn chỉnh càng sớm càng tốt. tức là từ việc lấy data source, xử lý dữ liệu, feature engineering, train, test, prediction, lưu trữ kết quả dự đoán hằng ngày hoặc hằng tuần cần được hoàn thành và vận hành mượt mà ngay từ lúc đầu tiên.
- Kết nối kết quả của mô hình với business càng sớm càng tốt, từ đó giúp các bạn đánh giá được mức độ hiểu quả đóng góp từ quá trình xây dựng mô hình.
Các lưu ý này được chia làm 4 phần, mỗi phần sẽ bao gồm một số rules các bạn cần lưu ý mà mình hay gặp phải ở một số công ty tại Việt Nam
Trước khi xây dựng mô hình Machine Learning
Rule 1: Nếu một vấn đề có thể giải quyết bằng những heuristic đơn giản thì hãy nghĩ ngay đến việc cài đặt điều đó trước.
Trong giải quyết một vấn đề, nếu các bạn cảm thấy rằng vấn đề đang xem xét có thể được giải quyết một phần nào bằng những heuristic đơn giản thì nên xây dựng một pipeline với phần mô hình được cài đặt là những logic đó trước hết. Điều đó giúp các bạn có thể hoàn thành một pipeline nhanh chóng, và nghĩ đến các vấn đề quan trọng khác như đo đếm các chỉ số của kinh doanh để thấy được hiệu quả, hoặc tìm cách thuyết phục các bên liên quan sử dụng kết quả của mình.
Ngoài ra, khi bắt đầu một dự án data science ở Việt Nam. Rất nhiều trường hợp bạn chưa có dữ liệu nhưng vẫn phải xây dựng mô hình vậy thì giải pháp lúc đó là sử dụng các heuristic đơn giản nhé. Sau khi đi vào vận hành, các bạn sẽ có thêm dữ liệu và hãy nghĩ đến các bước xây dựng mô hình machine learning thật sự.
Rule 2: Hãy suy nghĩ và cài đặt các metrics để đo đếm tính hiệu quả của mô hình của bạn đến việc kinh doanh.
Việc đo đếm các chỉ số kinh doanh trước khi có mô hình machine learning tác động giúp các bạn có thể so sánh với kết quả sau khi sử dụng các kết quả của bạn. Đo đếm các chỉ số này trước giúp các bạn có được cái nhìn tổng quan về các chỉ số mà bạn muốn tối ưu. Tuy nhiên ở những công ty mình làm, việc xác định chỉ số bên kinh doanh cần tối ưu thường không rõ ràng, vì những mục tiêu thường hay bị thay đổi khi các bạn thảo luận với các bên liên quan. Do đó, tốt nhất là nên biết chắc những gì mình làm và giữ vững lập trường.
Rule 3: Chọn một mô hình machine learning thay vì một heuristic phức tạp
Chúng ta khi giải quyết vấn đề thường chọn một mô hình machine learning, tuy nhiên trong một số trường hợp team leader lại thích sử dụng rule hơn. Điều đó dẫn đến mâu thuẫn cực lớn giữa các thành viên với nhau. Do đó, hãy chắc chắn rằng nếu bạn đang làm giải quyết các bài toán phức tạp thì hãy thuyết phục team leader sử dụng một mô hình machine learning vì điều này tạo ra nhiều lợi ích về sau như tính scale của bài toán, dễ cập nhật và maintain một mô hình machine learning hơn là một heuristic phức tạp.
Xây dựng pipeline đầu tiên.
Rule 4: Đảm bảo xây dựng pipeline tốt ngay từ đầu với một mô hình đơn giản
Chúng ta thường xem nhẹ việc xây dựng một pipeline tốt và thường tập trung thời gian vào việc xây dựng mô hình machine learning ngày từ lúc đầu. Lý do đơn giản bởi vì chúng ta yêu thích việc xây dựng một hình thông minh hơn là làm những công việc nhàm chán như xây dựng một quy trình để kết nối các bước như thu thập dữ liệu hàng ngày, xử lý dữ liệu, train, đổ kết quả dự đoán lại cơ sở dữ liệu và cho phép chúng có thể chạy tác vụ cũng như huấn luyện mô hình hàng ngày mà không cần sự tác động của chúng ta.
Khi xây dựng pipeline trước cho phép ta giải quyết các vấn đề liên quan đến data engineering từ đó giúp tăng tốc quá trình xây dựng mô hình nhanh chóng hơn ở các bước tiếp theo. Do đó, hãy bình tĩnh, không nên nóng vội lao đầu vào xây dựng một mô hình siêu to phức tạp, mà nên tập trung hầu hết thời gian lúc đầu để xây dựng pipeline vững chắc.
Rule 5: Hãy bắt đầu với một mô hình dễ giải thích.
Mô hình đơn giản cho phép chúng ta phát hiện các lỗi trong quá trình thu thập dữ liệu. hoặc phân tích tại sao lại có sự khác biệt giữa quá trình dự đoán lúc huấn luyện và trên môi trường production lại không giống nhau như mong đợi. Chúng ta có thể xem xét sử dụng linear regression hoặc logistic regression vì những mô hình này có thể hoàn toàn giải thích được kết quả dự đoán của nó, và trong nhiều ngữ cảnh, chúng quan tâm đến việc giải thích kết quả của quá trình dự đoán hơn chỉ là xác suất của mô hình.
Feature Engineering
Rule 6: Hãy launch mô hình đầu tiên với tập features vừa đủ và sau đó liên tục cập nhật mô hình
Các bạn không nên đợi đến khi xây dựng một mô hình vừa ý với đầy đủ các features vì như thế rất tốn kém thời gian mà lại không thấy kết quả đem lại từ mô hình của bạn cho kinh doanh. Do đó, hãy bắt đầu với mô hình đơn giản và tập features tối thiểu và nghĩ đến kế hoạch cập nhật thêm các features ở những giai đoạn tiếp theo.
Rule 7: Bắt đầu với các features đơn giản, dễ hiểu, xuất phát từ các heuristic thay vì các features từ mô hình deep learning.
Hầu hết các bài toán của data science đều đã được nghiên cứu tìm hiểu trong cộng đồng, do đó các bạn nên tham khảo những lời giải hay các features mà đã được cộng đồng sử dụng. Đồng thời, cố gắng chuyển cách common-sense trong quá trình tìm hiểu vấn đề thành các features thay vì nghĩ đến những features phức tạp như learned features ngay từ đầu nếu như điều đó không cần thiết.
Rule 8: Chú ý đến việc training/serving skew
Nếu bạn thấy độ chính xác trong quá trình train/validation với lúc chạy trên product có sự khác biệt lớn thì có thể do các nguyên nhân sau.
- Phân bố của nhãn cần dự đoán thay đổi. Nguyên nhân là lúc huấn luyện bạn đã không xem xét kĩ phân bố thực sự của nhãn cần dự đoán trong quá trình chạy thực tế.
- Phân bố của các dữ liệu, features thay đổi, có các features dễ bị thay đổi theo thời gian.
Nếu sự khác biệt của dữ liệu trong quá trình train/serving khác nhau. Bạn cần ý thức được và cần thay đổi pipeline, tổng hợp features làm sao cho hạn chế sự khác biệt đó. Hãy đảm bảo không có sự khác biệt nhiều giữ độ chính xác trên tập validation và lúc serving.
Bài viết mình kết thúc tại đây. Hy vọng những chia sẽ của mình về những kinh nghiệm trong quá trình làm những dự án data science cho công ty sẽ giúp ích cho các bạn.