
Hướng dẫn sử dụng DORI để nhận dạng các thông tin chính - Key Information Extraction using DORI
Trong bài viết này, mình sẽ hướng dẫn bạn cách sử dụng DORI để nhận dạng và trích xuất các thông tin quan trọng từ tài liệu. Chẳng hạn, nếu bạn cần xác định Họ Tên và ID trên căn cước công dân, thì hai thông tin đó chính là mục tiêu mà bạn muốn mô hình nhận dạng. Về cơ bản, quy trình thực hiện gồm các bước chính sau:
- Thu thập dữ liệu: Giả sử bạn đã có sẵn tập dữ liệu đầy đủ. Nếu chưa, bạn cần tiến hành thu thập dữ liệu trước.
- Đánh nhãn dữ liệu: Đây là quá trình con người can thiệp để gắn nhãn các thông tin mà mô hình cần học. Để trích xuất thông tin chính, bạn cần đánh nhãn các thành phần:
- Phát hiện văn bản
- Nhận dạng văn bản
- Xác định thứ tự đọc (không bắt buộc)
- Trích xuất thông tin chính
- Huấn luyện mô hình: Huấn luyện mô hình máy học trên tập dữ liệu đã được gán nhãn ở bước trên.
- Kiểm tra kết quả nhận dạng: Đánh giá mô hình sau khi huấn luyện để xem kết quả đã đạt yêu cầu chưa. Nếu chưa, có thể thực hiện gán nhãn bổ sung và huấn luyện lại.
Thực hiện thủ công các bước trên đòi hỏi rất nhiều thời gian, chi phí, và công sức—từ chi phí đánh nhãn, quản lý dữ liệu, phát triển giải pháp, đến huấn luyện mô hình và cập nhật khi dữ liệu mới xuất hiện. Nếu bạn muốn nhận dạng hàng chục loại giấy tờ khác nhau, khối lượng công việc và thách thức sẽ gia tăng đáng kể.
Trong quá trình phát triển nhiều mô hình nhận dạng khác nhau, mình nhận thấy rằng các bài toán này luôn tuân theo một quy trình chuẩn. Từ những kinh nghiệm tích lũy, mình đã xây dựng DORI – một nền tảng end-to-end chuyên cung cấp các giải pháp nhận dạng văn bản toàn diện. DORI không chỉ giúp rút ngắn thời gian xây dựng mô hình mà còn hỗ trợ tạo ra các giải pháp chất lượng cao, đáp ứng nhu cầu của cả cá nhân lẫn doanh nghiệp. Với khả năng xử lý hiệu quả và giao diện thân thiện, DORI tối ưu hóa quy trình xây dựng mô hình nhận dạng văn bản, giúp bạn giảm thiểu chi phí, tiết kiệm thời gian và đảm bảo tiêu chuẩn chất lượng cao nhất cho các giải pháp OCR – đặc biệt là trong ngôn ngữ tiếng Việt.
DORI không chỉ đơn thuần là một công cụ để hỗ trợ các nhân, chính phủ trong công cuộc chuyển đổi sổ mà còn đóng vai trò như một “baseline” chuẩn mực để cộng đồng cùng tham khảo và nâng cao chất lượng trong các bài toán nhận dạng tiếng Việt. Nổi bật với các tính năng sẵn có như:
- Giao diện đánh nhãn dữ liệu trực quan: Giúp bạn dễ dàng xử lý và quản lý dữ liệu.
- Quy trình huấn luyện tự động: Đơn giản hóa việc huấn luyện mô hình chỉ với vài thao tác.
- Công cụ triển khai và kiểm thử mô hình: Tích hợp các bước từ huấn luyện đến triển khai để đánh giá hiệu quả.
- Mô hình pretrained cho tiếng Việt và tiếng Anh: Tăng tốc độ đánh nhãn và huấn luyện, giảm thiểu khối lượng công việc thủ công.
Để sử dụng DORI, các bạn truy cập trang chủ tại dorify.net. Sau đó, chọn Đăng nhập hoặc Đăng ký nếu chưa có tài khoản. DORI hỗ trợ đăng nhập dễ dàng bằng tài khoản Google hoặc bằng tài khoản tự tạo.
Sau khi hoàn tất đăng nhập, các bạn sẽ được đưa đến giao diện chính, nơi quản lý tất cả các dự án của mình. Bạn hãy chọn ngôn ngữ ưu thích tiếng Việt/Anh tại góc trái dưới. Sau đó, để bắt đầu một dự án mới, các bạn thực hiện các bước sau:
Bạn có thể tham khảo video tóm tắt dưới đây về cách sử dụng DORI để nhận dạng thông tin chính
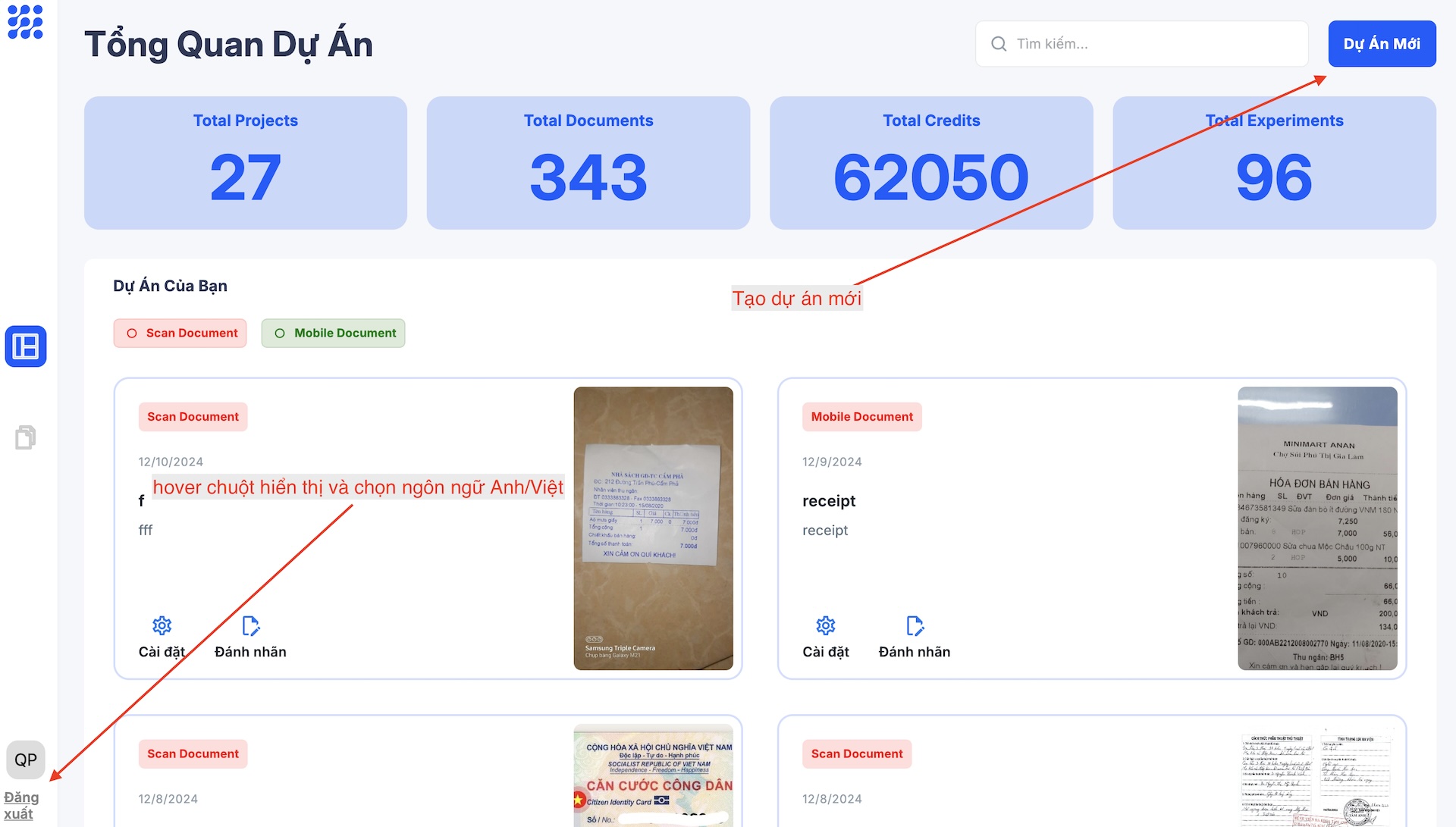
Tạo Dự Án Mới
Đầu tiên, hãy tạo một dự án mới trên DORI bằng cách nhấn vào Create Project, sau đó điền tên dự án, mô tả và phân loại. Hãy chọn hai công cụ cơ bản là text detection và key information extraction, ngoài 2 công cụ cơ bản ngoài DORI, còn cung cấp các công cụ khác như Phân loại văn bản, Phân tích bố cục, Xác định cấu trúc bảng, Rút trích mối quan hệ, v.v. Tiếp theo, nhấn vào Upload Image để chọn các ảnh cần đánh nhãn.
Gợi ý: Bạn có thể bắt đầu với 20 ảnh cho dự án thử nghiệm nhỏ và từ 100-300 ảnh để huấn luyện mô hình phục vụ thực tế. Không cần tải lên tất cả ảnh ngay từ đầu, bạn có thể bổ sung thêm trong phần Setting của dự án sau này. Sau khi tải lên ảnh, hệ thống sẽ tự động chạy mô hình phát hiện văn bản mặc định để giúp giảm thời gian đánh nhãn.
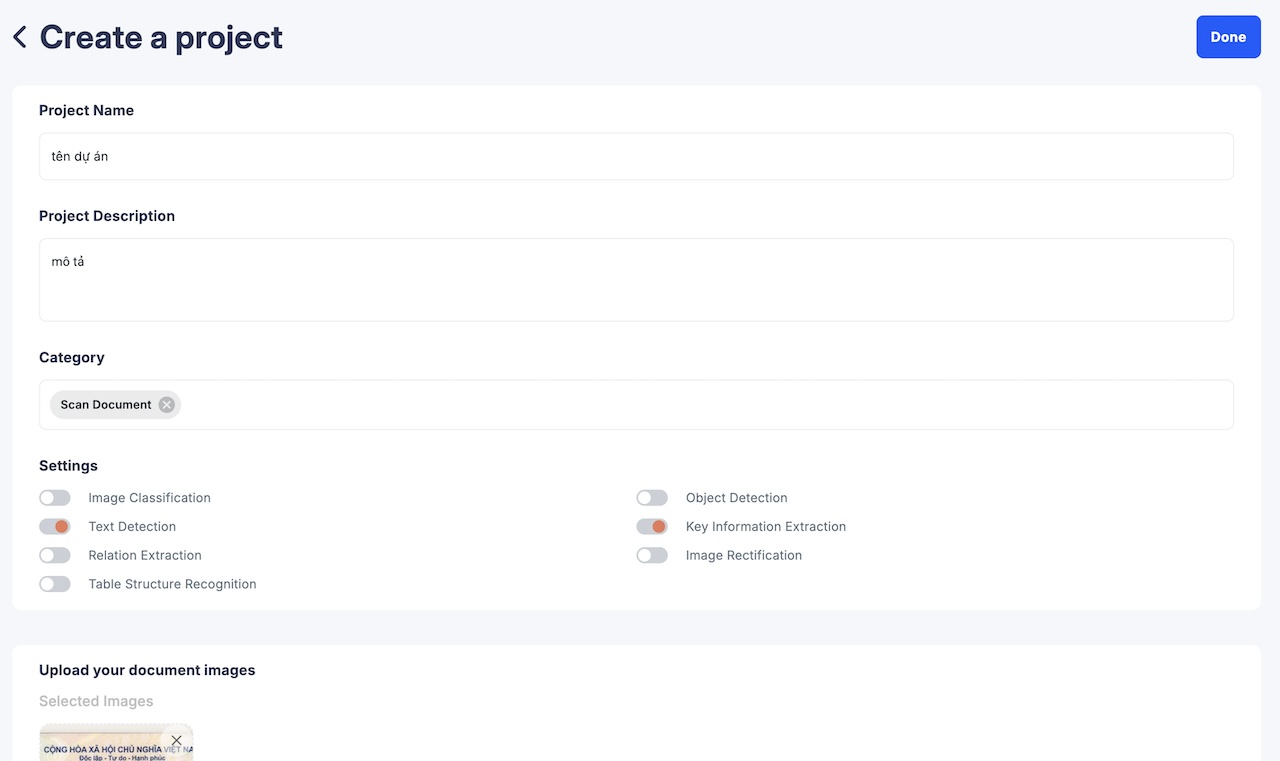
Nhấn Done để hoàn tất bước tạo dự án.
Sau đó, bạn nhấn vào Label để bắt đầu đánh nhãn các ảnh vừa tải lên, do bạn đã chọn 2 tool text detection và key information extraction nên trên giao diện đánh nhãn sẽ hiển thị 2 công cụ để giúp bạn đánh nhãn cho các bài toán này. Cụ thể về chức năng của 2 công cụ này sẽ mô tả chi tiết ở phần tiếp theo.
Đánh Nhãn
Đánh nhãn là bước quan trọng để tạo dữ liệu mẫu phục vụ huấn luyện mô hình, và cách thực hiện sẽ thay đổi tùy vào từng bài toán và mô hình cụ thể. Việc sử dụng các công cụ đánh nhãn chuyên biệt sẽ giúp mình và các bạn tiết kiệm rất nhiều công sức. Tại DORI, mình đã phát triển một công cụ đánh nhãn được tối ưu riêng cho các bài toán văn bản, đồng thời khắc phục những hạn chế của các công cụ hiện có.
Một trong những bước mất nhiều thời gian nhất khi xử lý OCR là xác định và đánh nhãn từng từ. Với những văn bản chứa hàng trăm từ, việc này có thể khiến các bạn tốn rất nhiều công sức. Để giải quyết điều đó, tại DORI, sau khi bạn tải ảnh lên, hệ thống sẽ tự động chạy OCR để nhận dạng từ, dòng, và đoạn văn bản. Đồng thời, hệ thống cũng nhận dạng nội dung của từng phần, giúp các bạn tiết kiệm đáng kể thời gian chuẩn bị dữ liệu. Ngoài ra, các mô hình nhận dạng và phát hiện văn bản tại DORI đã được huấn luyện trước trên hàng trăm nghìn mẫu dữ liệu, nên các bạn chỉ cần đánh nhãn một số lượng rất nhỏ – thậm chí chỉ khoảng 10 ảnh – là đã có thể huấn luyện mô hình với kết quả tốt.
Để rút ngắn thời gian hơn nữa, DORI cho phép các bạn sử dụng mô hình vừa huấn luyện để tự động gán nhãn cho tập dữ liệu chưa được đánh nhãn. Vì mô hình mới này được huấn luyện trên chính dữ liệu của bạn, kết quả sẽ chính xác hơn so với mô hình mặc định.
Với quy trình này, việc đánh nhãn để huấn luyện mô hình phát hiện, nhận dạng, và sắp xếp thứ tự đọc văn bản sẽ trở nên dễ dàng và hiệu quả hơn rất nhiều.
Quay trở lại với các bước cụ thể trong quá trình đánh nhãn để huấn luyện mô hình phát hiện, nhận dạng và xác định thứ tự đọc của văn bản.
Phát hiện, Nhận dạng và xác định thứ tự đọc của văn bản (Text Detection, Recognition & Reading Order)
Phát hiện văn bản là gì? (Text Detection) : Đây là bước xác định các vùng có chứa văn bản trong ảnh hoặc tài liệu bằng cách tạo các hộp giới hạn (bounding boxes, box) xung quanh các từ
Nhận dạng văn bản là gì? (Text Recognition): Sau khi xác định được vùng chứa văn bản, bước tiếp theo là nhận dạng nội dung trong các vùng đó, chuyển đổi hình ảnh chữ thành văn bản số mà máy tính có thể xử lý, thường sử dụng các mô hình OCR (Optical Character Recognition).
Có lẽ các bạn đã quen với việc cần phải xác định box và nội dung trong đó, Ở DORI, mình thiết kế công cụ đánh nhãn không chỉ giúp các bạn đánh từng từ dễ dàng mà còn cho phép xác định dòng/đoạn/page một cách dễ dàng thành thao tác group. Ở DORI, mình định nghĩa:
- Dòng văn bản (Line) là các từ có liên quan với nhau được sắp xếp theo tạo độ x ( ví dụ như tên sản phảm, địa chỉ, v.v.v tóm lại là những từ nên được gộp chung trên 1 dòng để tạo dành một cụm từ có nghĩa)
- Đoạn văn bản(Paragraph) là các dòng liên quan với nhau nên được sắp xếp theo tạo độ y để tạo ra một đoạn có nghĩa.
- Trang văn bản(Page)* là các tập hợp các từ/dòng/đoạn để tạo thành một trang, thông thường, các bạn chỉ cần nhóm tới level Paragraph là đủ, chỉ những file pdf/ảnh chứa nhiều trang mới cần tới level Page
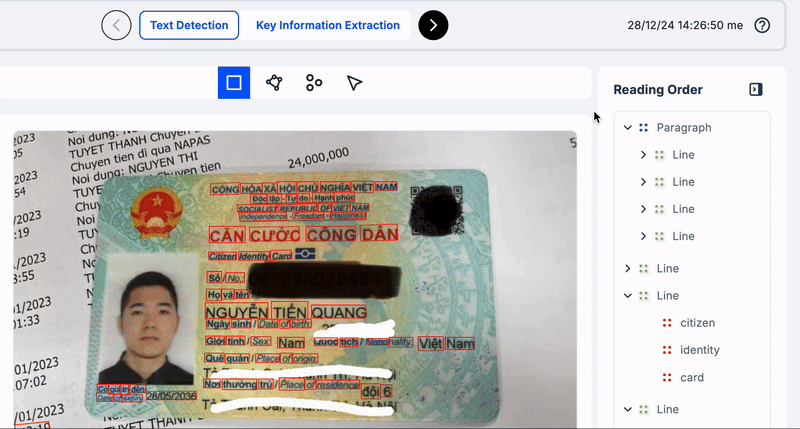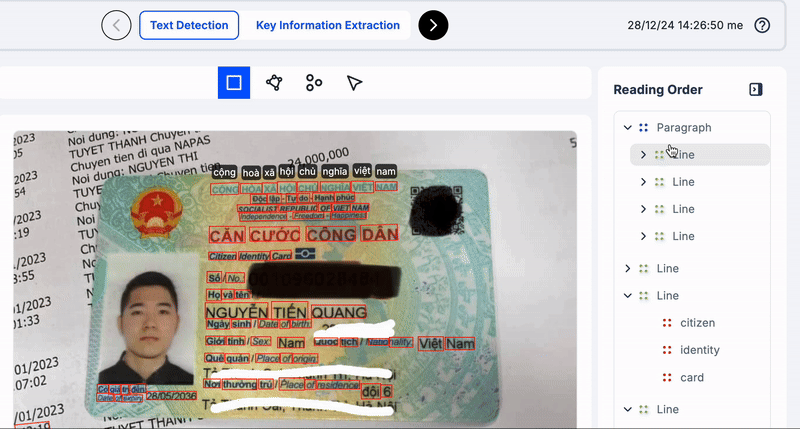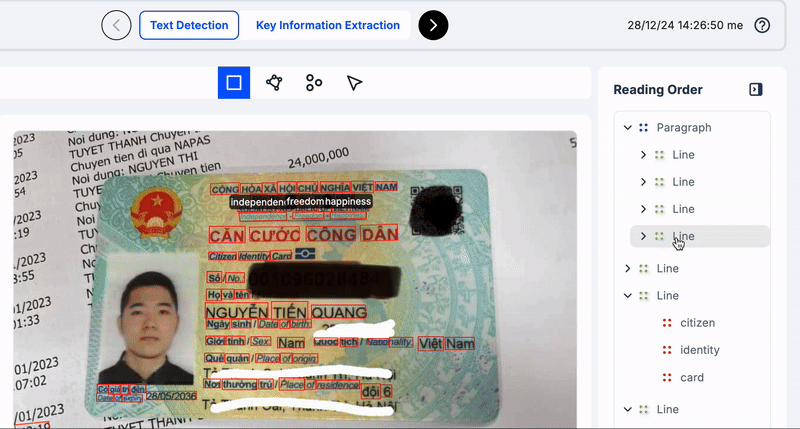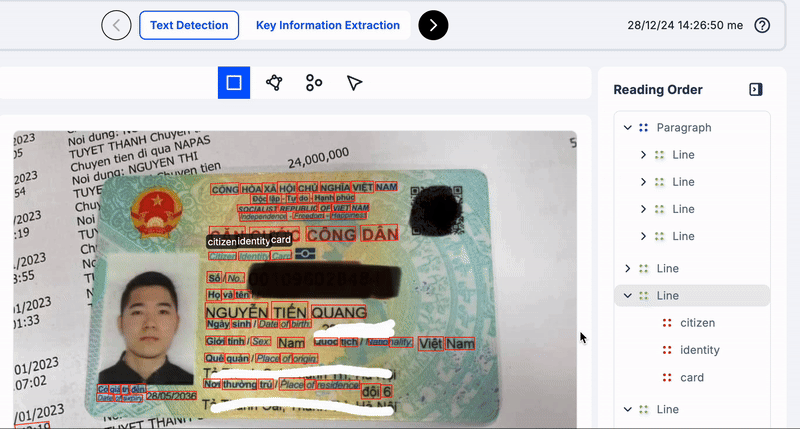
Để hiểu rõ hơn các bạn xem những ví dụ ở dưới đây về việc nên nhóm dòng/đoạn/trang văn bản như nào cho tốt.
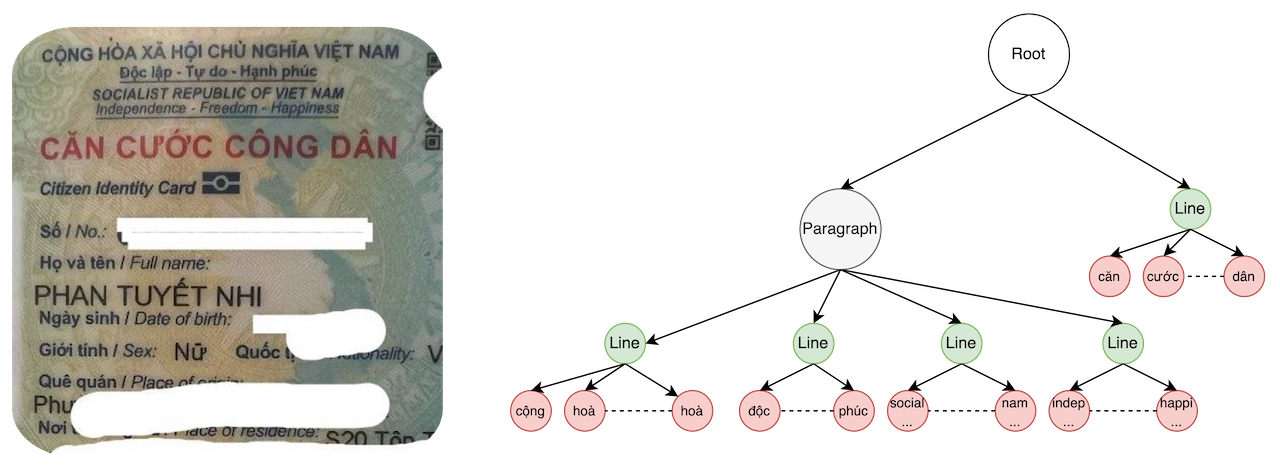
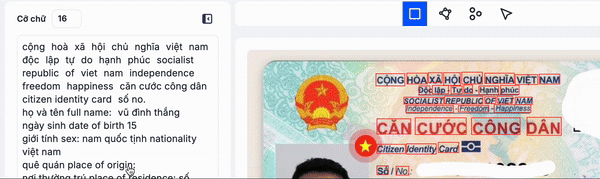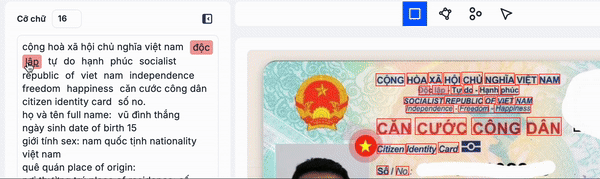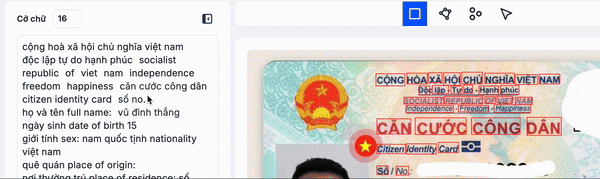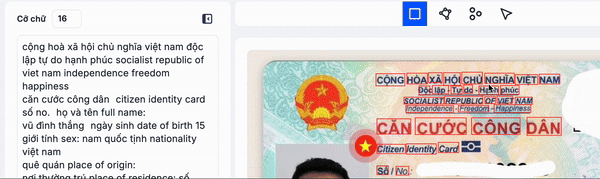
Trong minh hoạ trên, các bạn thấy mình nên group các từ cộng đến hoà, độc lâp đến hạnh phúc, căn cưới công dân, v.v.v thành một dòng vì chúng là các cụm có nghĩa và để đảm bảo thứ tự đọc chính xác
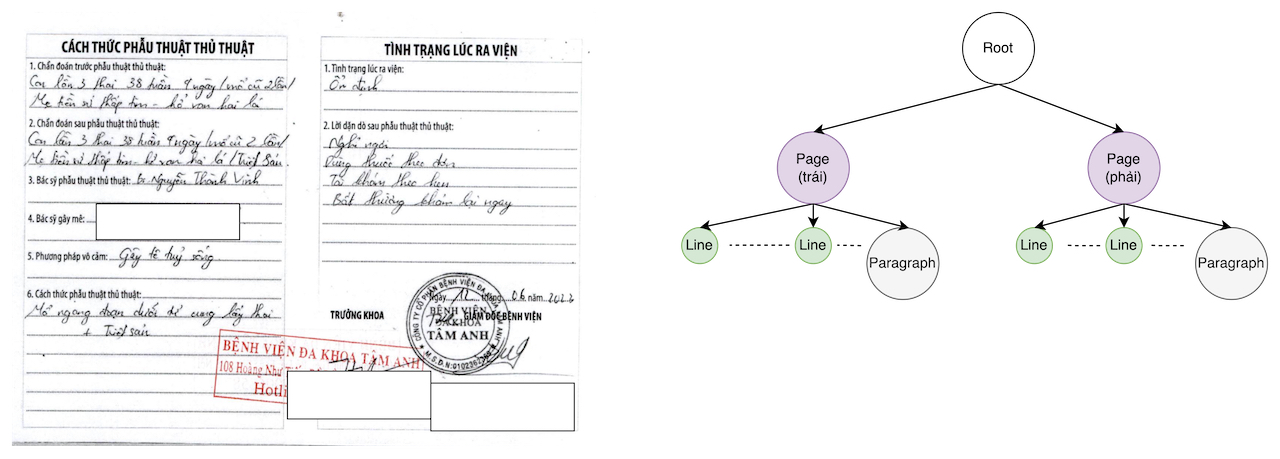
Ở mình hoạ này, các bạn thấy file văn bản có 2 trang rõ ràng, nên lúc này cần group các từ/dòng/đoạn tương ứng lại thành một trang.

Xem minh họa này, các bạn sẽ thấy rằng nếu không nhóm các từ, dòng, đoạn thành page thì các từ nằm ở hai trang khác nhau có thể bị nối nhầm với nhau. Lý do là thứ tự đọc mặc định sẽ theo hướng từ trái sang phải, trên xuống dưới. Hãy tưởng tượng thông tin như Tên Họ bị nằm không liên tục – điều này chắc chắn sẽ ảnh hưởng đến độ chính xác khi nhận dạng thông tin chính. Do đó, bước nhóm (group) này rất quan trọng.
Các bước nhóm ở trên giúp tạo thành cấu trúc hier text (cấu trúc phân cấp văn bản), từ đó hỗ trợ xác định đúng thứ tự đọc cho văn bản. Thứ tự đọc đúng này ảnh hưởng lớn đến khả năng nhận dạng thông tin chính ở các bước sau. Tại DORI, mình đã phát triển một mô hình có thể xác định tới 4 cấp độ (từ, dòng, đoạn, trang) chỉ bằng một mô hình duy nhất. Trong khi đó, hầu hết các mô hình hiện có như Google hoặc AWS thường chỉ hỗ trợ đến cấp dòng hoặc trang, nhưng lại không hoạt động hiệu quả với tiếng Việt.
Theo mình quan sát, phần lớn các loại giấy tờ chỉ cần nhóm đến cấp đoạn (paragraph) là đủ để xác định thứ tự đọc. Chỉ khi văn bản có nhiều trang như minh họa ở trên, các bạn mới cần xem xét việc nhóm thêm cấp trang (page).
Ở DORI, mình cho phép các bạn hover qua các từ/dòng/đoạn/page của văn bản ở reading order panel bên phải, giúp các bạn dễ dàng review tính chính xác của quá trình group .
Mặc dù chúng ta đã xác định được dòng, đoạn, và trang của văn bản, nhưng đôi khi thứ tự đọc vẫn có thể bị sai nếu chỉ dựa vào các thông tin này. Ví dụ, với hóa đơn bị nghiêng hoặc văn bản có nhiều cột, việc sắp xếp các từ theo cách thông thường sẽ không đủ. Trong trường hợp này, chúng ta cần sử dụng mô hình reading order để xác định đúng thứ tự đọc. Tại DORI, mình cũng cho phép các bạn tự sắp xếp từng từ để xác định chính xác thứ tự đọc của văn bản, từ đó dùng dữ liệu này để huấn luyện mô hình reading order.
Phần tiếp theo mình sẽ làm rõ reading order model là gì?
Xác định thứ tự đọc là gì? (Reading Order Detection)
Trong các tài liệu phức tạp, nếu chỉ dựa vào vị trí tọa độ và các nhóm như dòng, đoạn, hoặc trang, thì thứ tự đọc vẫn có thể không được xác định chính xác. Do đó, các bạn cần xây dựng mô hình xác định thứ tự đọc, nhằm hỗ trợ việc trích xuất dữ liệu một cách chính xác hơn.
Ví dụ dưới đây minh họa để các bạn thấy rằng thứ tự đọc đúng nên là từ trên xuống trước, sau đó mới từ trái qua phải. Về cơ bản, mô hình reading order sẽ xác định xem từ nào nên được đọc trước và từ nào nên đọc sau, từ đó đảm bảo thứ tự đọc chính xác nhất cho văn bản.

Để đánh nhãn cho mô hình reading order, DORI cho phép bạn di chuyển vị trí các từ để xác định lại thứ tự đọc, sau đó mô hình reading order dựa vào thông tin đó để học.
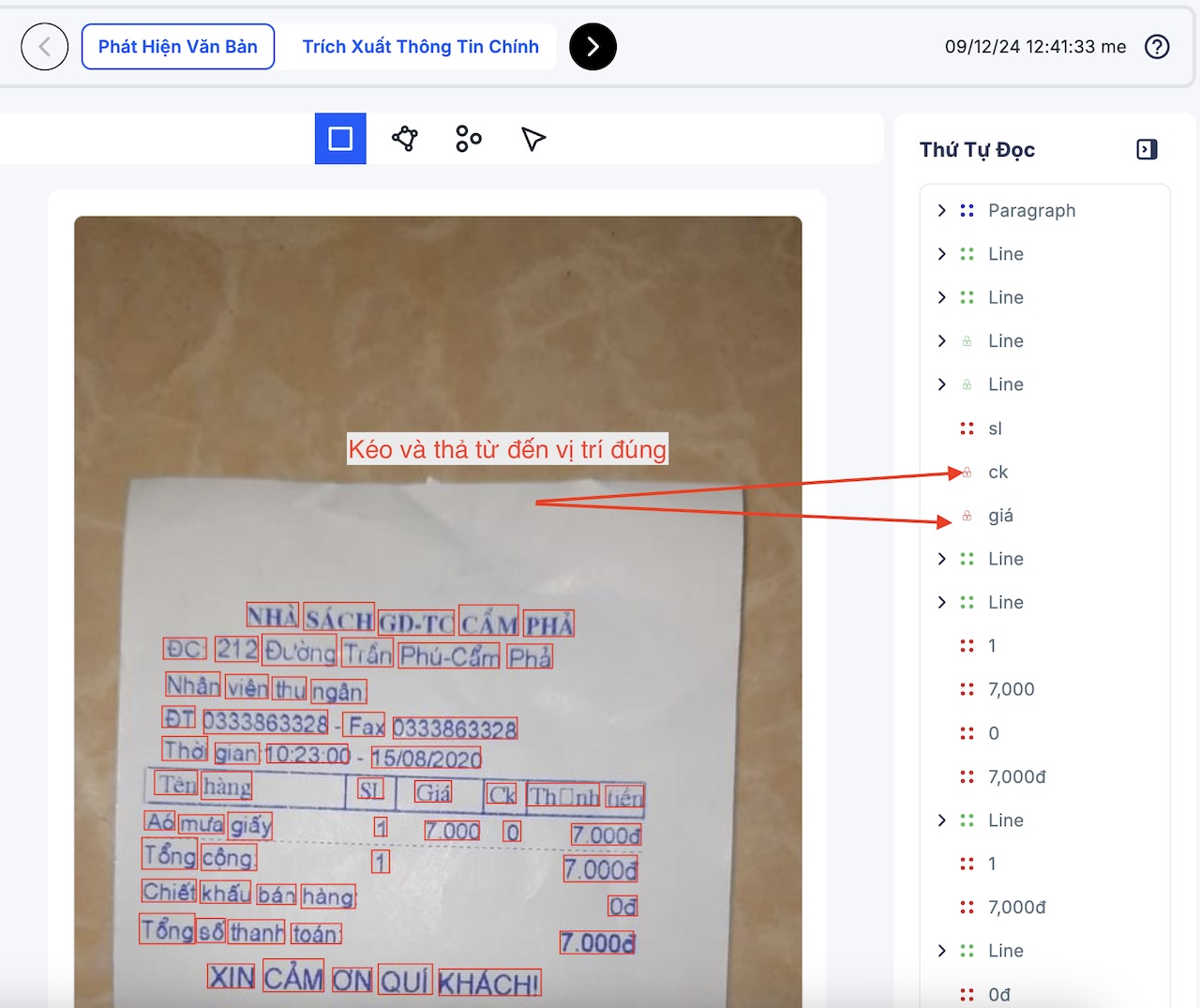
Với DORI, mình tích hợp ba bước này trong một công cụ gọi là Text Detection. Công cụ này hiển thị các từ cùng với vị trí box của chúng. DORI cung cấp hai loại box cơ bản: rectangle và polygon. Với các văn bản thông thường, chỉ cần chọn rectangle là đủ, còn các chữ phức tạp mới cần dùng polygon.
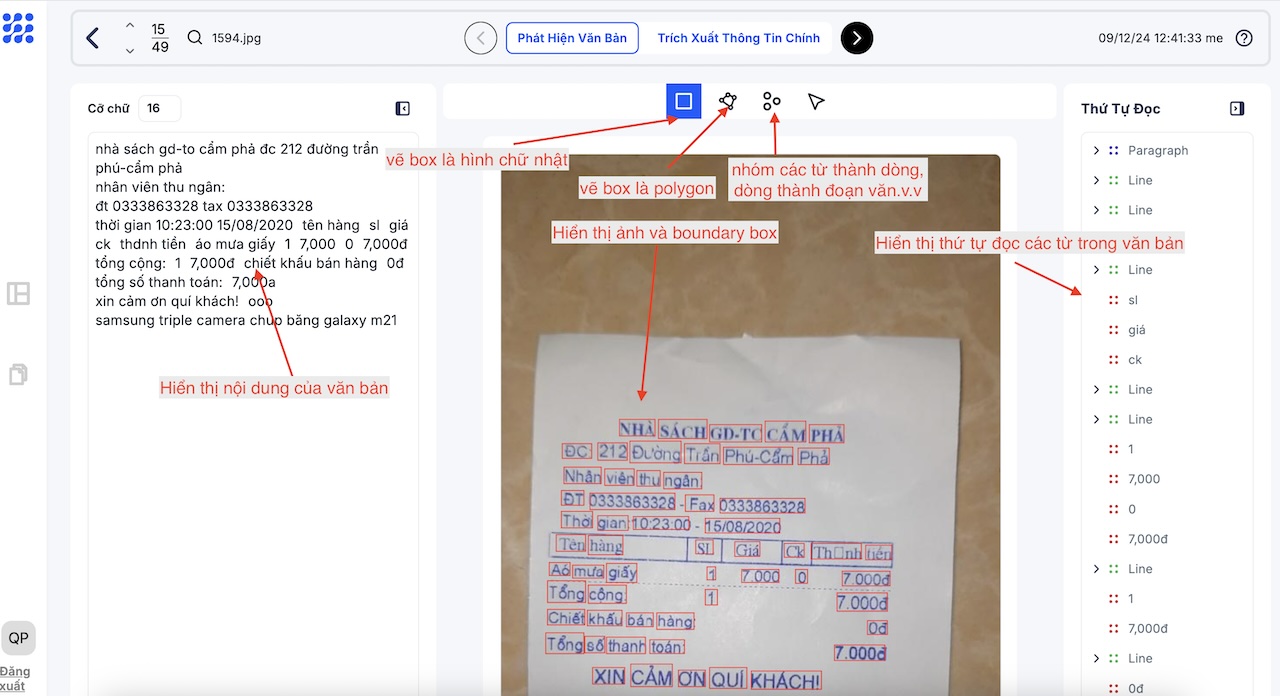
Khi vẽ hộp xong, bạn sẽ được yêu cầu nhập nội dung văn bản. Nội dung này sẽ hiển thị ở phần document bên trái và reading order bên phải, giúp bạn dễ dàng theo dõi, nhóm các từ thành dòng, dòng thành đoạn, và đoạn thành trang. Bạn cũng có thể thay đổi vị trí các từ để xác định đúng thứ tự đọc.
Tại DORI, mình hỗ trợ các bạn thao tác linh hoạt hơn bằng cách cho phép chọn từng từ, sau đó right-click để nhóm (group) lại thành dòng. Các bạn có thể tiếp tục nhóm từ và dòng thành đoạn, hoặc nhóm các dòng lại với nhau thành đoạn, rồi tiếp tục thành trang, tùy theo nhu cầu. Đặc biệt, để việc nhóm dễ dàng hơn, mình còn hỗ trợ các bạn thực hiện trực tiếp trên phần hiển thị ảnh, giúp quá trình thao tác trở nên trực quan và nhanh chóng hơn.
Clip dưới là minh hoạ group các từ/dòng/đoạn bằng cách select từng từ/dòng
Clip dưới minh hoạ cách group từ/dòng/đoạn bằng cách select bên phần ảnh

DORI sẽ hiển thị các màu khác nhau để phân biệt giữa dòng, đoạn và trang. Khi bạn chọn (select) một phần văn bản ở khu vực document hoặc reading order, các từ tương ứng trong phần ảnh sẽ được đánh dấu, giúp bạn kiểm tra nhanh chóng và chính xác.
Ngoài ra, khi bạn di chuột (hover) qua các từ trong phần ảnh, nhãn của hộp (box) đó sẽ được hiển thị, giúp bạn dễ dàng kiểm tra thông tin. Nếu muốn thay đổi nhãn, bạn chỉ cần click vào hộp đó, chỉnh sửa nội dung, và nhấn Enter để lưu thay đổi. Trong trường hợp cần ẩn hộp nhập liệu để dễ dàng điều chỉnh kích thước hộp, bạn chỉ cần nhấn Esc.
Với các tính năng này, DORI hỗ trợ bạn kiểm tra và chỉnh sửa một cách trực quan và hiệu quả hơn, giúp tối ưu hóa quy trình đánh nhãn.
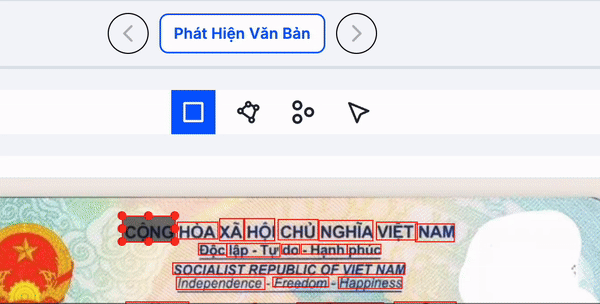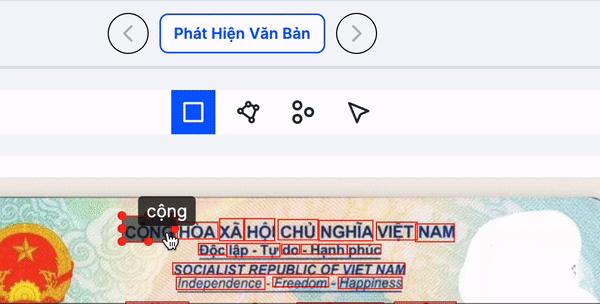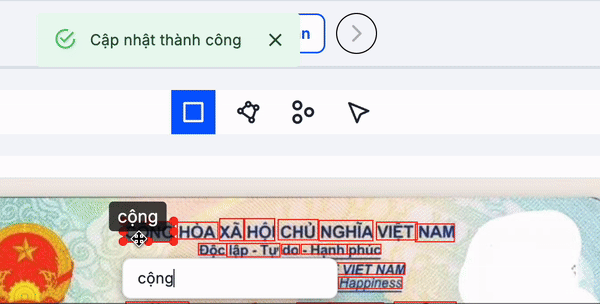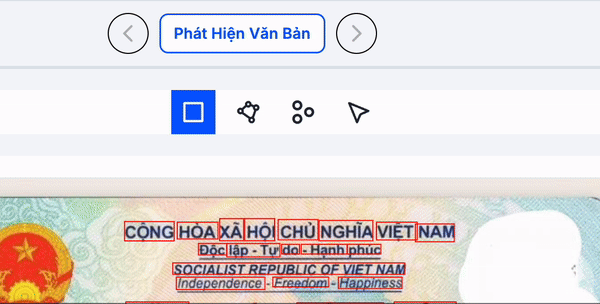
Làm như nào để đánh nhãn ở bước này chính xác?
Khi vẽ boundary box, các bạn cần vẽ cho từng từ, không phải cho từng ký tự, cũng không phải cho từng câu hay đoạn. Boundary box cần bao phủ chính xác từng từ, đảm bảo không thiếu dấu câu hay nét chữ và không được chồng lấn (overlap) với các boundary box khác.
Các bạn có thể tham khảo minh họa bên dưới. Hình bên trái cho thấy các boundary box được vẽ chính xác, bao phủ đầy đủ dấu câu và nét chữ của từng từ. Ngược lại, hình bên phải minh họa các boundary box bị vẽ thiếu chính xác, bỏ sót dấu câu hoặc nét, điều này sẽ ảnh hưởng trực tiếp đến kết quả nhận dạng.

Sau khi đánh nhãn xong thì bước tiếp theo là xác định các key information mà bạn muốn nhận dạng.
Trích xuất Thông tin Chính (Key Information Extraction)
Trích xuất thông tin chính là gì?
Sau khi văn bản được nhận dạng và sắp xếp, bước tiếp theo là xác định các thông tin chính cần trích xuất. Ví dụ, nếu bạn cần rút trích Họ Tên và ID, bạn sẽ tạo nhãn cho hai loại thông tin này, sau đó chọn các cụm từ tương ứng trong văn bản để gán nhãn.
Các bạn có thể tham khảo video dưới đây để hiểu rõ hơn về cách thực hiện.

Làm như nào để đánh nhãn ở bước này chính xác?
Khi chọn các thông tin cần nhận dạng, các bạn cần chọn toàn bộ đối tượng đó trong văn bản. Ví dụ, nếu muốn đánh nhãn Nguyễn Văn A là Tên, bạn phải bôi đen liên tục cụm từ này, không được chọn riêng Nguyễn, Văn, và A tách rời.
Nếu Nguyễn Văn A không nằm liền nhau trên văn bản, bạn cần quay lại bước text detection để nhóm các từ thành dòng, dòng thành cụm, v.v. Hoặc, nếu việc nhóm không hiệu quả, bạn cần thay đổi thứ tự đọc để đảm bảo các từ liên quan được xử lý đúng.
Huấn luyện Mô Hình
Huấn luyện mô hình là quá trình sử dụng tập dữ liệu đã được đánh nhãn để xây dựng mô hình nhận dạng. Trên DORI, bạn có thể huấn luyện mô hình trên tập dữ liệu của mình bất cứ khi nào cần. Việc huấn luyện có thể thực hiện sau mỗi 10, 50, 100, hoặc 1000 mẫu dữ liệu, giúp bạn theo dõi độ chính xác của mô hình sau khi cập nhật hoặc bổ sung dữ liệu, hoặc khi muốn nhận dạng thêm các trường thông tin mới.
Cách bắt đầu huấn luyện trên DORI
- Truy cập cài đặt: Vào phần Setting, chọn Train.
- Chọn mô hình: Lựa chọn mô hình phù hợp với bài toán của bạn.
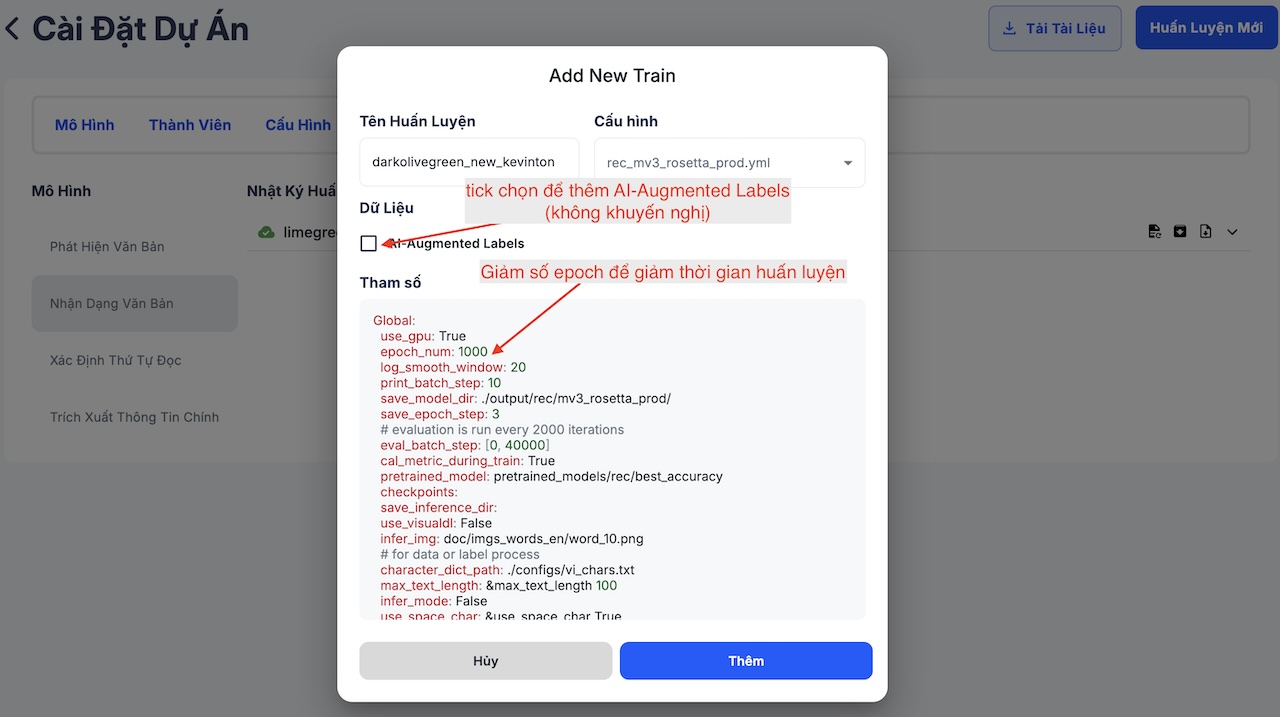
- Cấu hình tham số huấn luyện:
- Thông thường, bạn không cần thay đổi các tham số mặc định, ngoại trừ epoch_num (số lần hoàn thành huấn luyện trên toàn bộ dữ liệu). Việc điều chỉnh tham số này giúp giảm thời gian huấn luyện và tối ưu hóa chi phí.
- Nếu cần, bạn có thể tick chọn Include AI-Augmented Labels để bổ sung dữ liệu phát sinh tự động bởi mô hình. Tuy nhiên, mình khuyến nghị không nên chọn tùy chọn này trừ khi dữ liệu đã được đánh nhãn lại cẩn thận bởi labeler.
- Khởi động huấn luyện: Nhấn Add để bắt đầu quá trình huấn luyện mô hình.
Hệ thống sẽ gửi email thông báo khi quá trình huấn luyện bắt đầu và kết thúc. Bạn cũng có thể theo dõi lịch sử và độ chính xác của mô hình trong phần Log, giúp quản lý và đánh giá hiệu quả mô hình một cách dễ dàng.
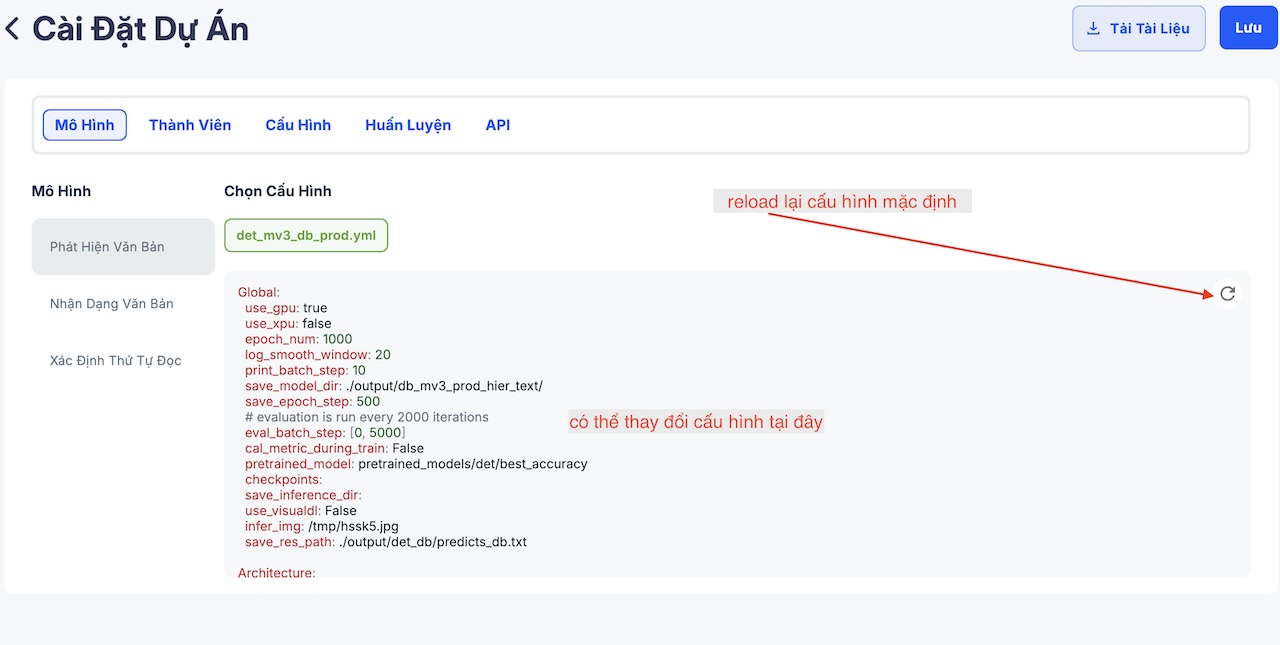
Mỗi mô hình có một cấu hình riêng, và bạn có thể xem cấu hình hiện tại bằng cách nhấp vào tab Model. Tại đây, bạn có thể thực hiện các thay đổi tùy chỉnh trong cấu hình. Những thay đổi này sẽ được tự động lưu lại.
Nếu cần quay lại cấu hình mặc định của mô hình, bạn chỉ cần nhấn nút reload ở góc phải. Điều này giúp bạn dễ dàng khôi phục cấu hình ban đầu khi cần.
Clip dưới đây minh họa quá trình tạo job để huấn luyện mô hình mới. Các bạn có thể dễ dàng theo dõi log và kiểm tra độ chính xác của mô hình bằng cách nhấn vào log.
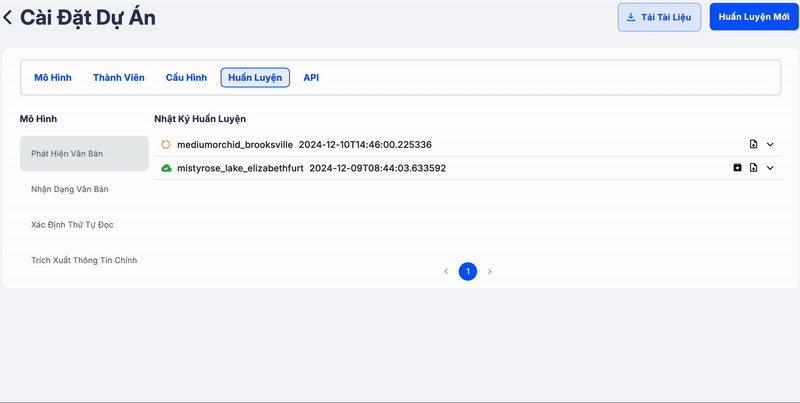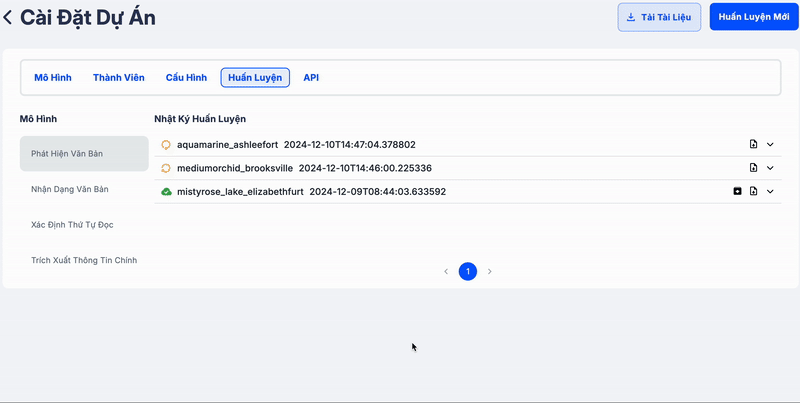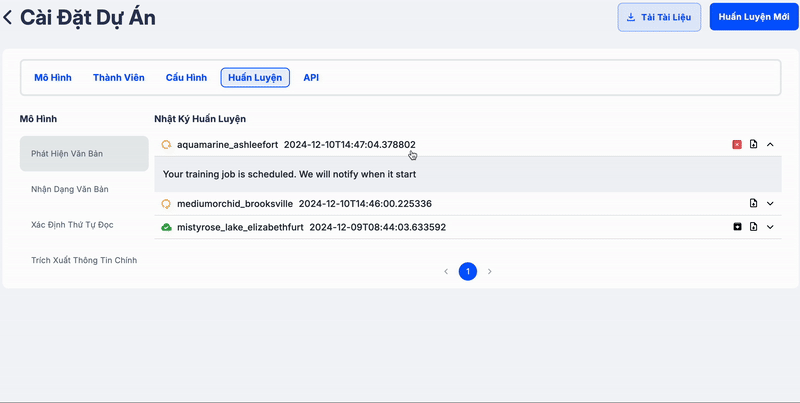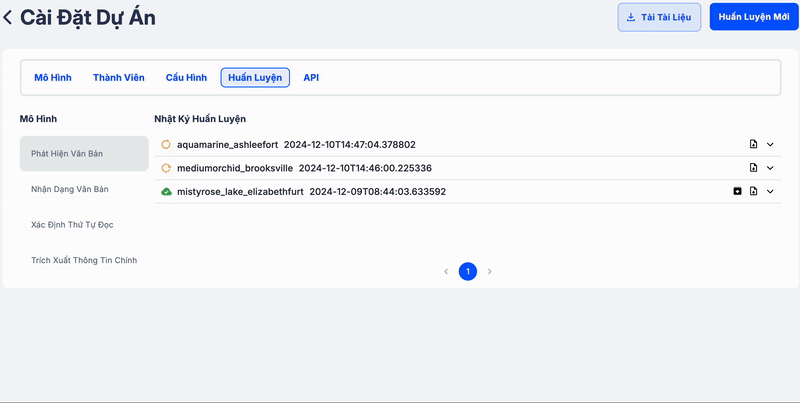
Phần log hiển thị các metrics quan trọng được đánh dấu bằng màu đỏ, giúp bạn dễ dàng nhận biết. Các metrics này càng lớn thì mô hình hoạt động càng tốt. Bên cạnh đó, log cũng cung cấp thông tin về các lỗi (nếu có), giúp bạn nhanh chóng phát hiện vấn đề và thực hiện các điều chỉnh cần thiết, hoặc yêu cầu hỗ trợ kịp thời.
Sau khi quá trình huấn luyện hoàn tất, mô hình của bạn sẽ được tự động deploy (triển khai) để sẵn sàng sử dụng. Các bạn hãy xem phần giải thích về giao diện bên dưới.
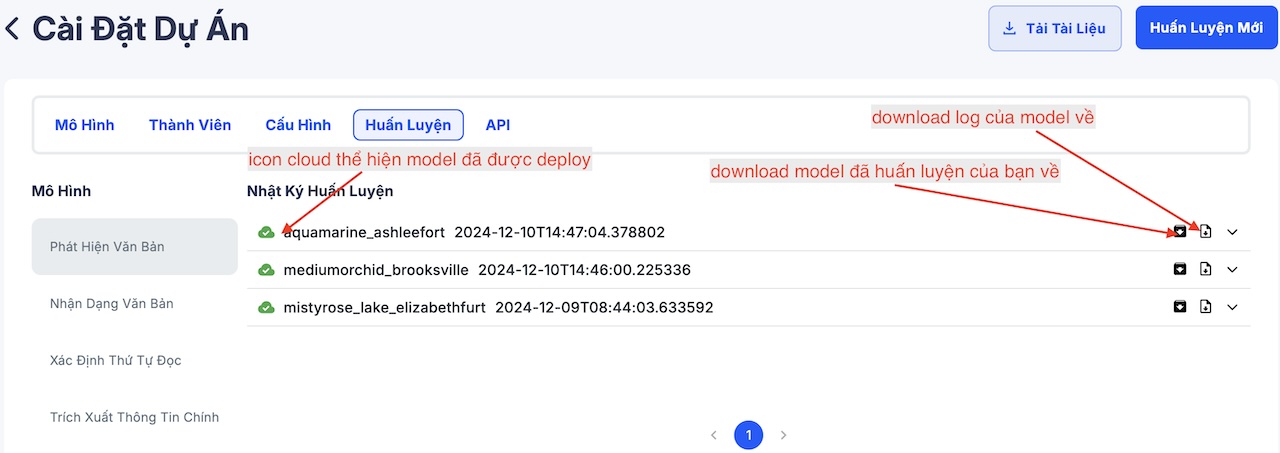
Sau đó bạn có thể dễ dàng kiểm tra mô hình vừa huấn luyện bên tab API
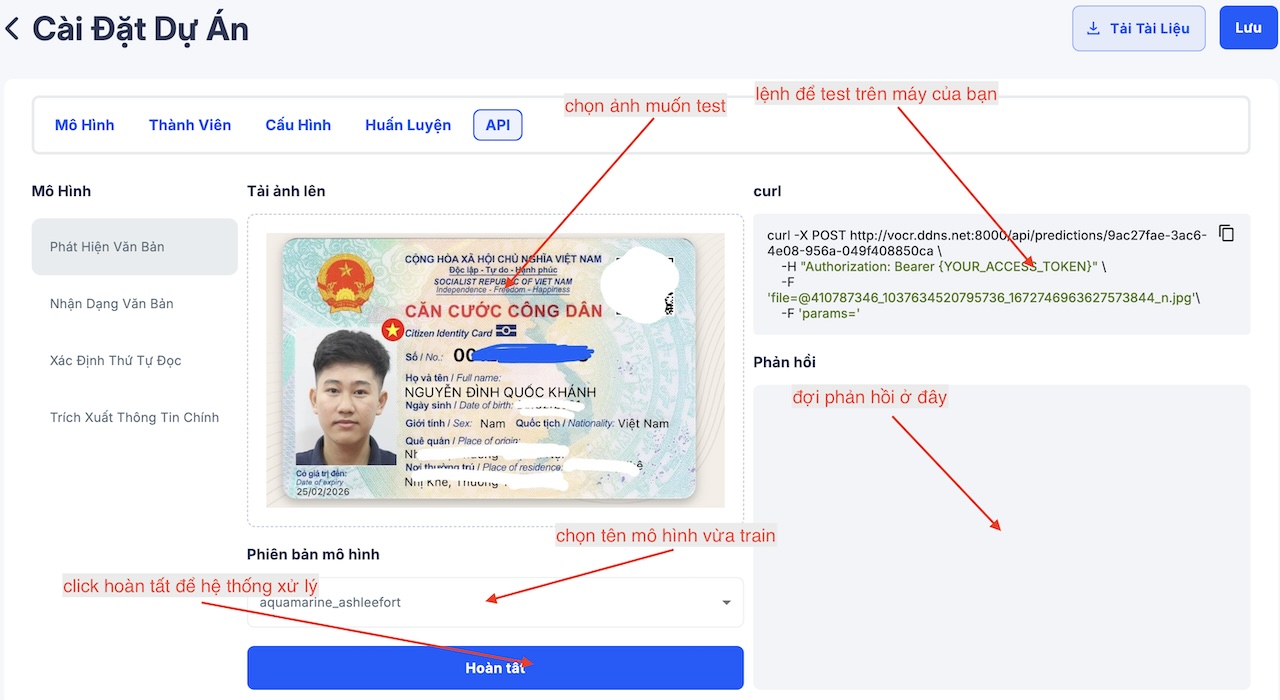
Hãy lặp lại quy trình trên, bao gồm các bước đánh nhãn, huấn luyện, và kiểm tra, lần lượt đối với từng mô hình: text detection, sau đó là text recognition, tiếp đến là reading order, và cuối cùng là key information extraction. Lưu ý rằng kết quả huấn luyện của các mô hình trước đó sẽ được sử dụng làm đầu vào cho các mô hình phía sau, do đó cần thực hiện tuần tự và chính xác.
Tại DORI, các bạn có thể dễ dàng huấn luyện mô hình chỉ với tập 10–20 ảnh ban đầu, sau đó tăng dần quy mô dữ liệu. Hãy tận dụng tính năng này để nhanh chóng có được kết quả ban đầu, từ đó thực hiện các điều chỉnh cần thiết hoặc tìm kiếm hỗ trợ từ mình. Nếu cần thêm thông tin, bạn có thể liên hệ qua website của DORI tại dorify.net để được tư vấn chi tiết.
Tip để tăng tốc quá trình đánh nhãn
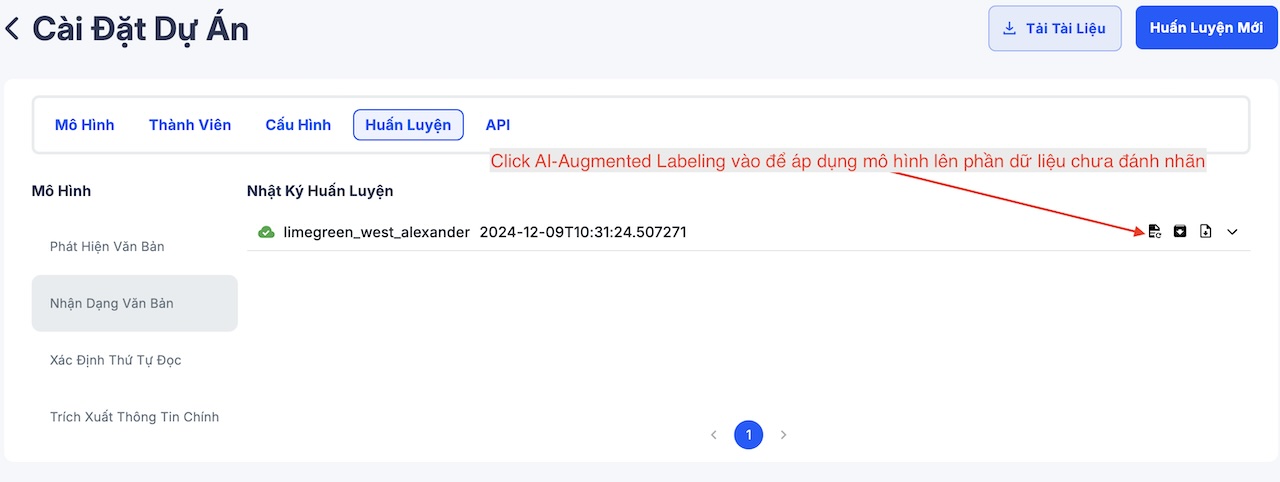
Quá trình đánh nhãn thường tốn nhiều thời gian và công sức, nhưng DORI cung cấp tính năng AI-Augmented Labeling để hỗ trợ bạn. Tính năng này cho phép tận dụng mô hình đã được huấn luyện trên dữ liệu đã đánh nhãn để tự động áp dụng vào phần dữ liệu chưa được đánh nhãn.
Thông thường, bạn chỉ cần đánh nhãn khoảng 10–20 mẫu, sau đó tiến hành huấn luyện mô hình trên tập dữ liệu này. Khi quá trình huấn luyện hoàn tất, bạn chỉ cần nhấn vào AI-Augmented Labeling để áp dụng mô hình đã huấn luyện lên phần dữ liệu còn lại chưa được đánh nhãn.
Cá nhân mình thường xuyên sử dụng tính năng này vì nó cực kỳ hữu ích, giúp tiết kiệm rất nhiều thời gian và tăng năng suất của cả nhóm.
Huấn luyện text detection, text recognition, reading order detection, key information extraction như nào?
Việc huấn luyện các mô hình như text detection, text recognition, và các mô hình khác trên DORI về cơ bản được thực hiện theo quy trình tương tự. Tuy nhiên, mình muốn nhấn mạnh rằng thứ tự huấn luyện là rất quan trọng.
Lý do là các mô hình ở các bước sau, chẳng hạn như text recognition hay key information extraction, sẽ sử dụng kết quả từ các mô hình đã được huấn luyện ở các bước trước. Vì vậy, cần tuân thủ trình tự huấn luyện để đảm bảo kết quả tốt nhất.
Hãy bắt đầu với text detection, tiếp theo là text recognition, rồi đến reading order, và cuối cùng là key information extraction. Thực hiện đúng thứ tự này sẽ giúp bạn xây dựng một pipeline hoạt động hiệu quả và chính xác.
Chạy offline mô hình của bạn.
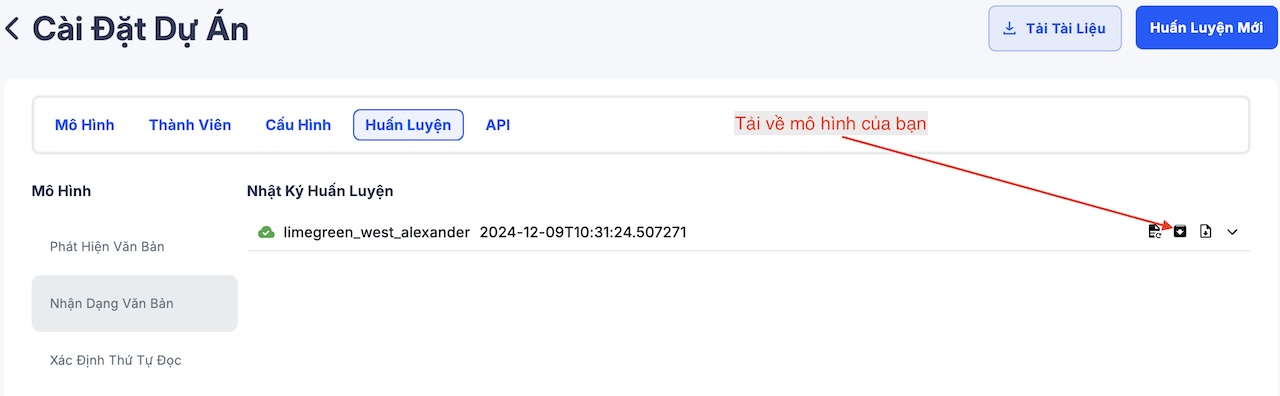
Sau khi hoàn tất quá trình huấn luyện, DORI cho phép bạn tải về mô hình của mình và chạy offline trên máy tính. Các mô hình do mình thiết kế đều được tối ưu hóa để chạy on-device, có dung lượng nhẹ (lightweight) và hiệu suất cao. Nhờ vậy, chúng có thể chạy mượt mà trên CPU, đồng thời đạt tốc độ xử lý thuộc hàng top đầu trên thị trường.
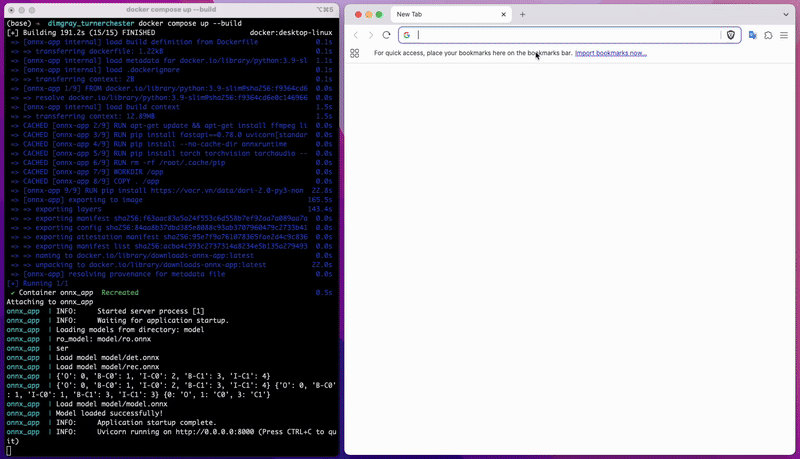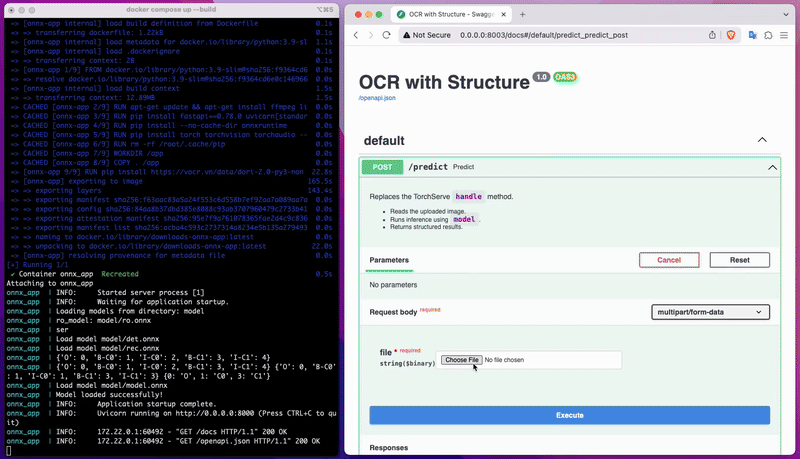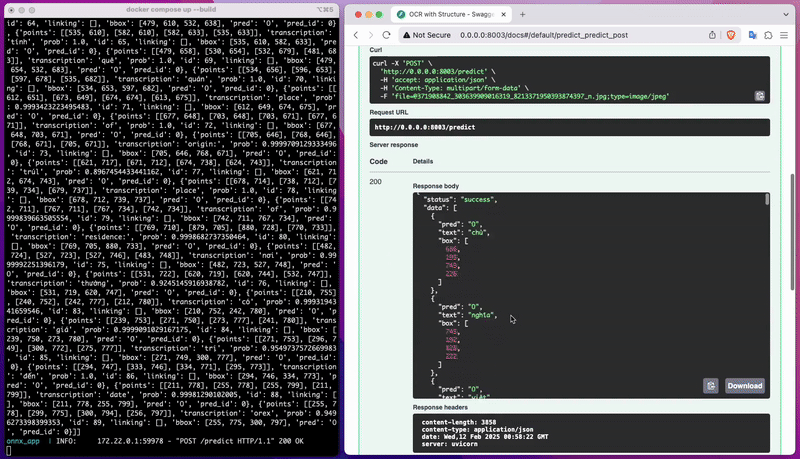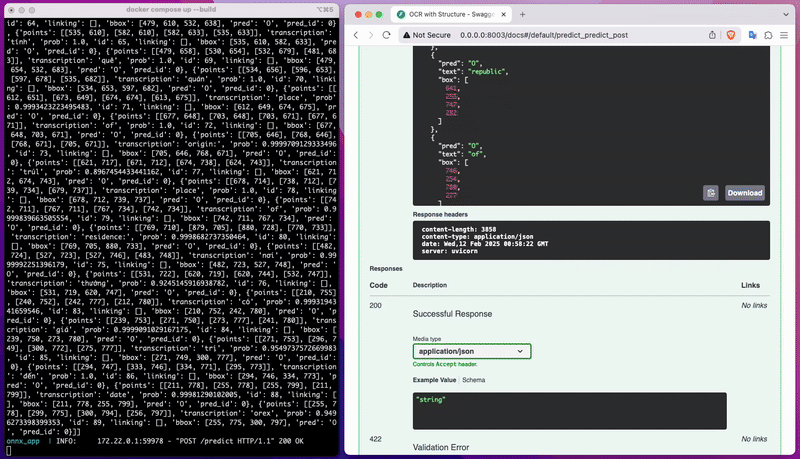
Để tải mô hình, bạn chỉ cần nhấn vào mô hình đã huấn luyện và tải về. Sau đó, làm theo hướng dẫn trong file README đi kèm để cài đặt và chạy mô hình hoặc xem 2 clip dưới để biết cách build docker image và chạy offline API cho mô hình của bạn.
Build docker image của bạn
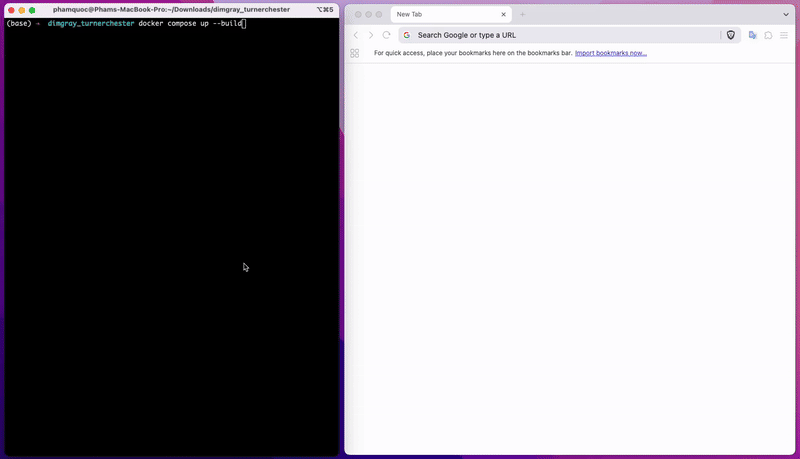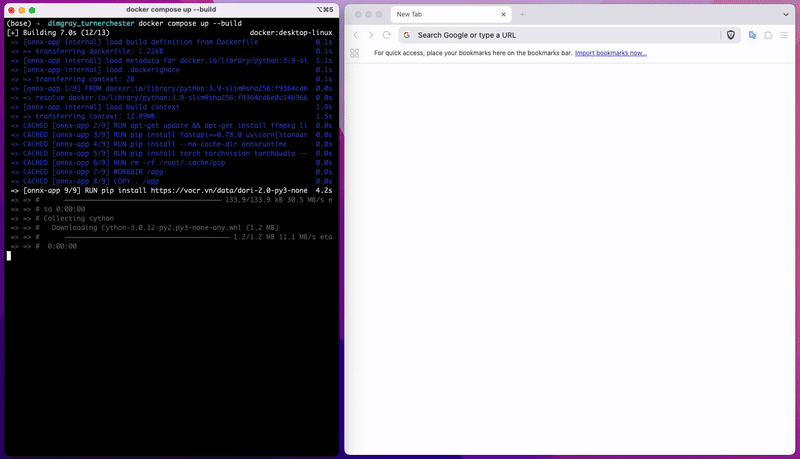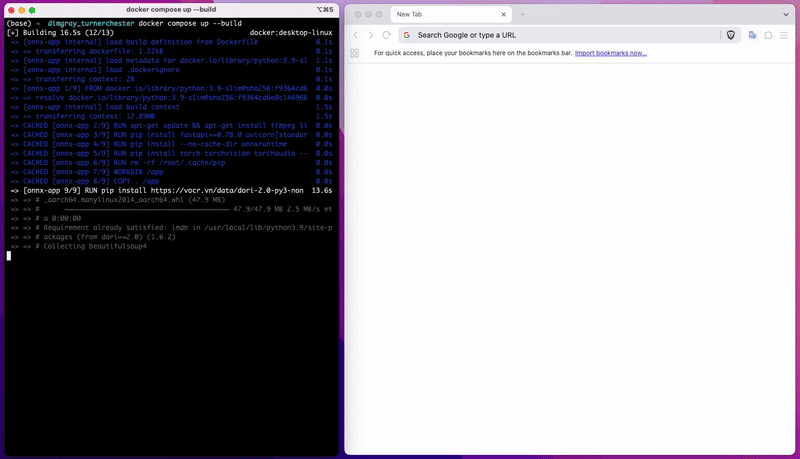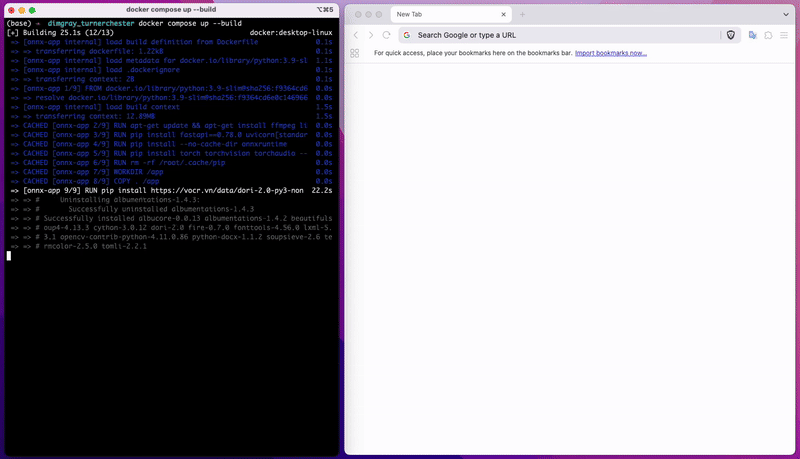
Truy cập API của mô hình vừa tải về
Các lỗi thường gặp
- Đánh quá ít dữ liệu: Thông thường các bạn cần tối thiếu 10 mẫu để huấn luyện là không báo lỗi.
- Ảnh đánh nhãn khác với ảnh chạy thực tế: Luôn đảm bảo rằng cách bạn thu thập ảnh để đánh nhãn giống với ảnh input cho mô hình khi chạy thực tế.
Ngoài các chức năng đã nêu, DORI còn cho phép bạn thêm thành viên vào dự án để cùng tham gia đánh nhãn, giúp tăng tốc độ và hiệu quả xử lý dữ liệu.
Bên cạnh đó, DORI còn hỗ trợ nhiều bài toán quan trọng khác như:
- Phân loại văn bản: Xác định loại tài liệu hoặc nội dung cụ thể.
- Xác định layout: Phân tích và nhận dạng bố cục của văn bản.
- Chỉnh phẳng ảnh: Xử lý hình ảnh bị cong hoặc nghiêng để cải thiện độ chính xác nhận dạng.
- Nhận dạng và xác định cấu trúc bảng: Tự động phát hiện và phân tích bảng biểu trong văn bản.
- Rút trích mối quan hệ: Tìm và trích xuất các mối liên hệ giữa các thông tin trong tài liệu.
DORI cung cấp một giải pháp toàn diện, đáp ứng hầu hết các nhu cầu xử lý văn bản trong thực tế, giúp bạn dễ dàng quản lý và xử lý dữ liệu phức tạp.