
Huấn luyện mô hình CRNN cho nhận dạng chữ viết tay Tiếng Việt - How to train your dragon.
Giới Thiệu

Nhận dạng chữ tiếng việt là một trong những vấn đề rất quan trọng và có nhiều ứng dụng trong lĩnh vực số hóa văn bản để lưu trữ, tìm kiếm trên các văn bản scan, ảnh. Mô hình Convolutional Recurrent Neural Network là mô hình phổ biến cho kết quả rất khả quan trọng việc nhận dạng chữ in cũng như chữ viết tay.
Trong blog này mình hướng dẫn các bạn huấn luyện một mô hình CRNN cho các bài toán nhận dạng chữ Tiếng Việt bằng mã nguồn mình cung cấp sẵn tại đây. Đồng thời, mình cũng cung cấp bộ dataset tự phát sinh gồm 4m ảnh và mô hình đã được huấn luyện sẵn trên tập dataset này. Mô hình này đạt kết quả khá tốt, và được mình sử dụng trong một số dự án thực tế.
Mô hình
Ở phần này mình chỉ trình bày tóm tắt kiến trúc mô hình.

Mô hình CRNN cho bài toán nhân dạng chữ viết tay trong cài đặt này là mô hình đơn giản bao gồm 2 phần: CNN và LSTM. Cụ thể CNN sẽ rút trích feature từ ảnh,kết quả sẽ cho ra tensor 3 chiều có kích thước batch_size x 1 x f. Do đó, các bạn cần lưu ý kiến trúc của CNN phải phù hợp để có thể nhận đầu vào có kích thước wxh và chiều w của tensor output có kích thước là 1. Để đưa tensor output vào LSTM, các bạn đơn giản chỉ cần remove w có kích thước là 1. Đến đây, các bạn áp dụng mô hình LSTM và dùng CTC loss để cập nhật trọng số.
Chuẩn bị dữ liệu
Để huấn luyện mô hình CRNN mà mình cung cấp trong repo này. Các bạn cần chuẩn bị data theo cấu trúc sau:
data/
├── 0.jpg
├── 0.txt
├── 10000.jpg
├── 10000.txt
Mỗi ảnh sẽ phải tương ứng với một file txt chưa nhãn tương ứng. Ví dụ với ảnh có tên file dưới đấy là 1.jpg, thì phải có một file 1.txt tương ứng chứa nhãn từ chối trả lời và nói không phản ứng gì dù những

Ngoaì ra các bạn cần có 3 file sau:
- train: chứa danh sách các file ảnh để train, đường dẫn tuyệt đối nhé.
- test: chứa danh sách các file ảnh để test, đường dẫn tuyệt đối nhé.
- chars: chứa các kĩ tự mà mô hình có thể predict, các bạn có thể tham khảo file char trong repo của mình chứa khoảng 245 kí tự phổ biến nhất.
Các bạn nên tham khảo thư mục data trong repo của mình để chuẩn bị dữ liệu cho chính xác nhé.
Huấn luyện
Sau khi chuẩn bị dữ liệu xong, các bạn đã có thể tiến hành huấn luyện mô hình cho tập dữ liệu của riêng mình. Để huấn luyện các bạn sử dụng câu lệnh sau:
python train.py --root /data --train train --val test --workers 8 --cuda --pretrain /data/quocpbc/tmp/netCRNN.pth --alphabet char --expr_dir checkpoint/
Trong đó:
- root: là thự mục chứa dữ liệu (file train/test/char).
- train: là file chứa các file ảnh để train.
- test: là file chứa các file ảnh để test.
- workers: số cores dùng để load dữ liệu, nên để bằng hoặc thấp hơn số cores của máy.
- pretrain: pretrain model, nên xử dụng vì tăng tính tống quát hóa của mô hình.
- alphabet: tập hợp tất cả các kí tự mà mô hình có thể predict.
- expr_dir: nơi lưu lại các mô hình được huấn luyện.
Kết quả
Kết quả sau khi huấn luyện các bạn có thể thấy ctc loss xấp xỉ 4 và cer loss < 0.1 là cho kết quả bình thường. Để predict dựa trên mô hình đã được huấn luyện, các bạn sử dụng câu lệnh sau:
python demo.py --model checkpoint/netCRNN.pth --alphabet /data/char --img /data/test.jpg --imgW 1024 --imgH 64
Trong đó:
- model: mô hình đã được huấn luyện.
- alphabet: chứa các kí tự mà mô hình có thể predict. Giống như file lúc train.
- img: ảnh dùng để test.
- imgH: với kiến trúc hiện tại thì tham số này có giá trị là 64
- imgW: default là None sẽ lấy kích thước của ảnh
Ví dụ với ảnh hưởng đây, mô hình sẽ cho ra kết quả như sau:
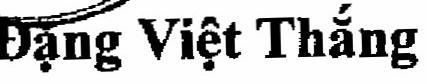
Kết quả: đđ-ặ–nngg vvviiệệtt tt–h–ắ–nnggg —-> đặng việt thắng : prob: 0.9896178245544434 prob là xác xuất của câu mà mô hình tính toán được. Giá trị còn nhỏ thì kết quả có thể sẽ không tin tưởng được.
Pretrained model và Dataset
Mình cung cấp mô hình pretrain trong repo được huấn luyện trên 4 triệu ảnh, bao gồm chữ in, viết tay, ảnh noise. Mô hình có thể predict 245 kí tự như mình cung cấp ở file char. Đồng thời các bạn có thể download toàn bộ dữ liệu 1 triệu ảnh tại này nhé.