
Nhận Dạng Chữ Tiếng Việt - Vietnamese OCR
Giới thiệu
Nhận dạng chữ viết tay là một trong những bài toán rất thú vị, với đầu vào là một ảnh chứa chữ và đầu ra là chữ chứa trong ảnh đó. Bài toán này tương đối khó đối với chữ viết tay, cộng với viết bộ dữ liệu việt nam tương đối hiếm có. Lần này, mình sẽ chia sẽ hướng tiếp cận mà team mình đã sử dụng trong cuộc thi do Cinnamon tổ chức, nhờ những cách sử lý hợp lý mà team mình đã đạt đượt top 1 trong phase 1 của cuộc thi này. Nhưng mà cuộc thì này tổ chức cũng dài hơi, làm những thí sinh hơi nản. (tầm 2 tháng với phần thi + bootcamp). Sơ qua về một chút ứng dụng của OCR. Mình thấy có 2 ứng dụng khá nổi tiếng là Google Translate, với GotIt của Hùng Trần.
Dữ liệu
Dữ liệu của bài toán này là chỉ có text-line không có scene text nên vấn đề đơn giản hơn nhiều so với việc phải detect được chữ trên ảnh có background như ngoài thực tế.

Chuẩn bị dữ liệu
Đối với văn bản scan thì việc tiền xử lý như remove noise,background là cực kì quan trọng và ảnh hưởng khá nhiểu đến độ chính xác của bài toán. Để remove noise và background thì các bạn có thể sử dụng kmean để cluster bức ảnh ra 2 màu chủ đạo trắng và đen rồi sau đó binary ảnh dựa vào kết quả cluster. Trong quá trình xử lý các bạn có thể sử dụng tool này nhé

Mô hình
Dữ liệu đã chuẩn bị xong thì đến phần model. Môt trong những mô hình được hay sử dụng là CRNN, tuy nhiên mô hình mình sử dụng thêm vào cơ chế attention cho phép model lựa chọn vùng ảnh mong muốn để phát sinh ra text. Cơ chế attention được sử dụng rất nhiều trong machine translation. Mình sẽ có một bài về cơ chế này,tuy nhiên các bạn có thể tham khảo tại đây.
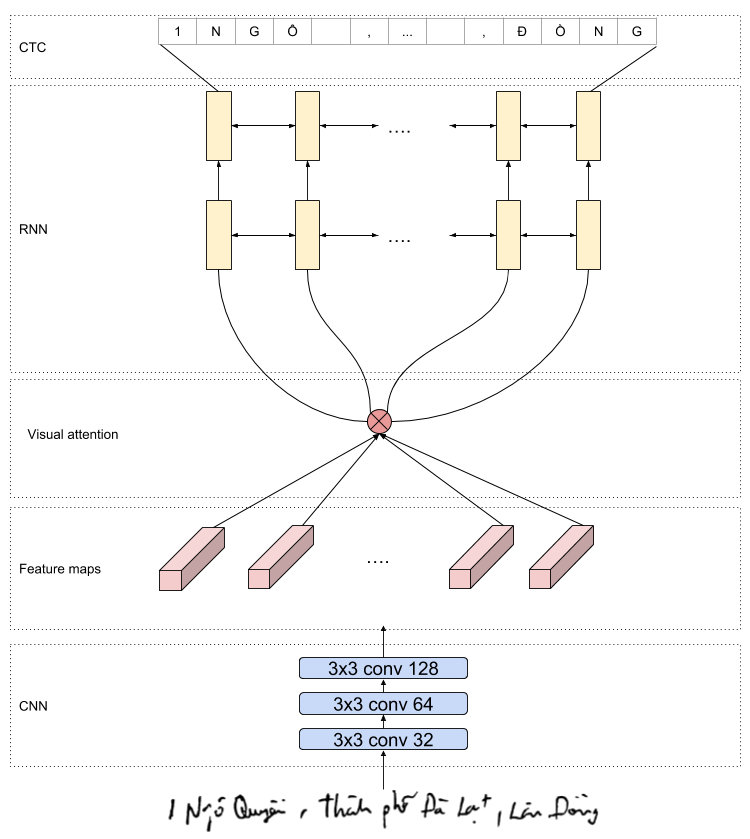
Đối dữ liệu là ảnh thì chúng ta sẽ dùng mô hình CNN để extract feature. Ở đây, mình dùng VGG16 nhé. Trong model hình này, chúng ta nên lưu ý số tầng pooling, mình chỉ sử dụng 4 tầng pooling của VGG16, mỗi tầng pooling sẽ có kích thước 2x2,đồng thời bỏ hết tất cả các tầng fully connected cuối cùng, do đó output của VGG16 là một tập các feature maps, mỗi pixel trên feature tương ứng vùng 16x16 trên bức ảnh đầu vào.

Việc chọn kích thước và số tầng pooling này cực kì quan trọng vì nó ảnh hưởng đến số pixel mà mỗi timestep nhìn thấy được.Nếu các bạn chọn kính thước tầng pooling size quá lớn sẽ dần đến việc một step sẽ bao gồm nhiểũ chữ trong ảnh do đó mô hình sẽ không nhận dạng được.
base_model = applications.VGG16(weights='imagenet', include_top=False)
Với ảnh đầu vào có kích thước 1280x60 thì output của vgg16 là (nmaps, w, h) = …, mỗi dòng tương ứng với chiều w thì tương ứng với một timstep cho tầng LSTM.
Visual attention
Với mô hình CRNN, kết quả của vgg được truyền trực tiếp vào mô hình LSTM, tuy nhiên, với thực nghiệp của mình khi stack thêm một lớp attention ở giữa tầng vgg và LSTM sẽ cho kết quả nhận dạng tốt hơn. Attention cho phép model của chúng ta được thoải mái lựa chọn kết hợp thông tin giữa các timestep khác nhau để tổng hợp lại và sử dụng đặc trưng tổng hợp này làm đầu vào để nhận dạng chữ cái. Cụ thể vector context được tổng hợp tại mỗi timestep như sau:
Đầu tiên ta cần tính e với e chính là output của Aligment Model, một dạng feedforward nets với input là trạng thái của networks hiện tại
Sau đó ta tính attention score tại mỗi timestep bằng hàm softmax vì chúng ta mong muốn tổng attention score bằng 1
Cuối cùng, context vector là weighted average của trạng thái ẩn với attention score.
def attention_rnn(inputs):
# inputs.shape = (batch_size, time_steps, input_dim)
input_dim = int(inputs.shape[2])
timestep = int(inputs.shape[1])
a = Permute((2, 1))(inputs)
a = Dense(timestep, activation='softmax')(a) // Alignment Model + Softmax
a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
output_attention_mul = multiply([inputs, a_probs], name='attention_mul') // Weighted Average
return output_attention_mul
LSTM
Với các vector context được tính ở tầng Attention được sử dụng là đầu vào cho mô hình LSTM. Tại mỗi timestep, chúng ta dự đoán từ tại thời điểm đó. Các timestep liên tục có thể dữ đoán cùng một từ.
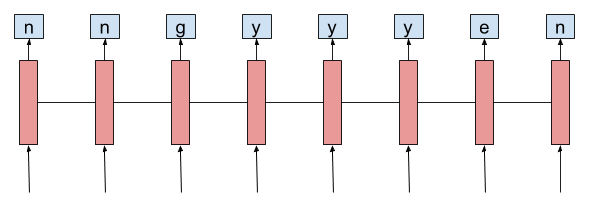
Connectionist Temporal Classification loss
Với dữ liệu huấn luyện, chúng ta có nhãn là một đoạn text tương ứng với chữ trong bức ảnh đó. Chúng ta không có nhãn cụ thể tại mỗi thời điểm từ xuất hiện là gì tương ứng với timestep trong mô hình LSTM, do đó chúng ta không thể dùng cross entropy loss để tính độ lỗi mà phải dùng CTC loss trong bài toán bài.
Encoding ground truth
CTC loss giải quyết vấn đề này theo cách rất là thông minh, cụ thể chúng ta sẽ thử tất cả các alignment của ground truth và tính score của tổng tất cả alignment. Alignment của ground truth được phát sinh bằng cách thêm blank token (-) và lặp lại bất kì kí tự nào trong ground truth.
Ví dụ ta có ground truth là: sun và có mô hình LSTM của chúng ta dự toán 4 timesteps. Thì những alignment đúng của ground truth là:
- sun -> -sun, s-un, su-n, sun-
- sun -> suun, ssun, sunn
Đới với những từ có 2 kí tự liên tục giống nhau, chúng ta sẽ thêm blank token để ở giữa để tạo ra một alignment đúng. Ví dụ với kí tự too. Các alignment đúng có thể là:
- too -> -to-o, tto-o
Nhưng ko thể là tooo.
Decoding text
Mô hình của chúng ta sẽ học để predict những alignment trên, sau đó chúng ta phải decode để đưa ra chuỗi dự đoán cuối cùng bằng cách gộp những kí tự lặp lại liên tiếp nhau thành một kí tự và sau đó xóa hết tất cả blank token. Ví dụ với alignment tto-o thì sau khi decode chúng ta sẽ có too bằng cách gộp 2 kí tự ‘t’ lại với nhau và xóa ‘-‘.
Tính CTC loss
Với mỗi grouth truth chúng ta có nhiều alignment, bất kì alignment nào được dự đoán đều là một dự đoán đúng. Do đó, hàm loss ta cần tối ưu chính là tổng của tất cả các alignment.
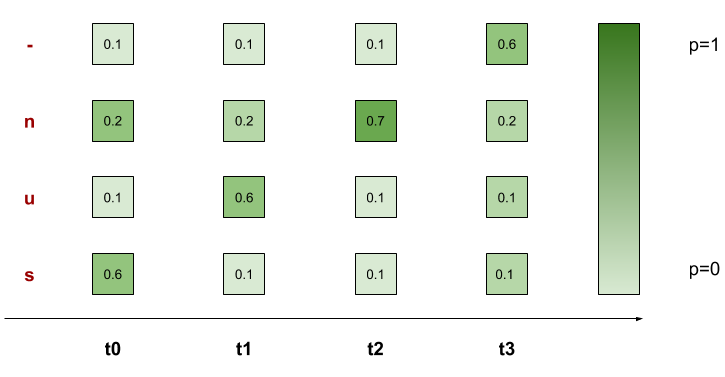
Với từ sun, ta có tổng 7 alignments đúng ở trên. Do đó theo model, xác suất từ sun xuất hiện là
Hàm loss của chúng ta sẽ là 1 - p(‘sun’)
Word Beam Search
Chúng ta có thể lựa chọn câu được phát sinh bằng best path, hoặc có thể bằng word beam search. Đối với best path, tại mỗi thời điểm chúng ta lựa chọn từ có xác suất lớn nhất. Tuy nhiên đối với cách này,câu được phát sinh có thể không phải là câu có xác suất cao nhất. Thay vào đó,chúng ta có thể sử dụng beam search để giữ tại N câu có xác suất lớn theo theo best path rồi cuối cùng câu được chọn sẽ là câu có sác xuất cao nhất trong N câu đó.
Đối với bài toán OCR, mỗi timestep sẽ phát sinh một kí tự do đó từ được phát sinh có thể không nằm trong từ điển. Đối trường trường hợp này, chúng ta có thể sử dụng một số phương phát post process để xử lý câu được phát sinh. Đơn giản, chúng ta sử dụng edit distance để so sánh khoảng cách 2 từ, và thay thế từ không nằm trong từ điển bằng từ có edit distance thấp nhất. Hay phức tạp hơn, chúng ta có thể dùng language model để sửa lỗi câu được phát sinh. Đối với python/tensorflow, các bạn có thể dùng thư viện sau để phát sinh câu từ model
OCR Data Augmentation
Trong cuộc thi này, tập dữ liệu mà BTC cung cấp chỉ có 2000 mẫu, do đó để huấn luyện model chúng ta cần sử dụng một số phương pháp để tăng dữ liệu.
- Xoay hay dịch chuyển một ít bức ảnh.
- Sử dụng elastic transform
- Random erasor một phần của bức ảnh.

Kết quả
Mình train 5 folds ,mỗi fold mất khoảng 8 tiếng để chạy. Sau khi chay khoảng 70-80 epochs thì WER khoảng 0.1x. Theo mình thấy thì kết quả tương đối chính xác. Có vẻ bộ dataset hơi dễ :))

Download dataset
Bộ dataset này là của Cinnamon. Mình không chịu trách nhiệm khi các bạn sử dụng sai mục đích.