
VietOCR - Nhận Dạng Tiếng Việt Sử Dụng Mô Hình Transformer và AttentionOCR

Giới Thiệu
Trong blog này, mình chia sẻ một số thực nghiệm của 2 mô hình OCR cho bài toán nhận dạng chữ tiếng việt: AttentionOCR và TransformerOCR. AttentionOCR sử dụng kiến trúc attention seq2seq đã được sử dụng khá nhiều trong các bài toán NLP và cả OCR, còn TransformerOCR sử dụng kiến trúc của Transformer đã đạt được nhiều tiến bộ vượt bậc cho cộng đồng NLP.
Một câu hỏi mà mình cũng khá quan tâm là Liệu TransformerOCR có mang lại kết quả vượt bậc như những gì các bạn đã nhìn thấy trong các bài toán NLP hay không ?
Đồng thời, mình cũng cung cấp một thư viện mới cho bài toán OCR, thư viện hướng tới kết quả chính xác, nhanh chóng, dễ huấn luyện, dễ dự đoán cho cả các bạn chưa có nhiều kinh nghiệm cũng có thể sử dụng được trong các bài toán liên quan đến số hóa.
Mô Hình
Trong phần này mình sẽ trình bày cách kết hợp mô hình CNN và mô hình Language Model (Seq2Seq và Transformer) để tạo thành một mô hình giúp các bạn giải quyết bài toán OCR. Chi tiết từng bước mô hình hoạt động, các bạn nên tham khảo những bài giới thiệu kiến trúc seq2seq của cộng đồng NLP vì mô hình này được ứng dụng khá nhiều và nổi tiếng.
Ngoài ra, mình cũng so sánh hạn chế của mô hình OCR cổ điển sử dụng CTCLoss với 2 mô hình kể trên từ đó giúp các bạn lựa chọn mô hình phù hợp trong các vấn đề thực tế.
CNN Của Mô Hình OCR
Mô hình CNN dùng trong bài toán OCR nhận đầu vào là một ảnh, thông thường có kích thước với chiều dài lớn hơn nhiều so với chiều rộng, do đó việc điều chỉnh tham số stride size của tầng pooling là cực kì quan trọng. Mình thường chọn kích thước stride size của các lớp pooling cuối cùng là wxh=2x1 trong mô hình OCR. Không thay đổi stride size phù hợp với kích thước ảnh thì sẽ dẫn đến kết quả nhận dạng của mô hình sẽ tệ.
Đối với mô hình VGG, việc thay đổi pooling size khá dễ do kiến trúc đơn giản, tuy nhiên đối với mô hình phức tạp khác như resnet việc điều chỉnh tham số pooling size hơi phức tạp do một ảnh bị downsampling không chỉ bởi tầng pooling mà còn tại các tầng convolution khác.
Trong pytorch, đối với mô hình VGG, các bạn chỉ đơn giản là thay thế stride size của tầng pooling.
cnn.features[i] = torch.nn.AvgPool2d(kernel_size=ks[pool_idx], stride=ss[pool_idx], padding=0)
AttentionOCR
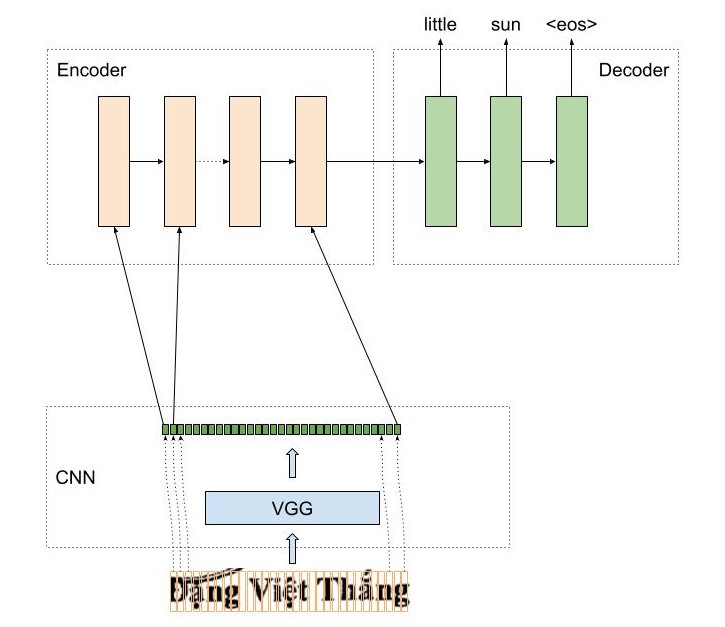
AttentionOCR là sự kết hợp giữa mô hình CNN và mô hình Attention Seq2Seq. Cách hoạt động của mô hình này tương tự như kiến trúc của mô hình seq2seq trong bài toán dịch máy. Với bài toán dịch máy từ tiếng việt sang anh, chúng ta cần encode một chuỗi tiếng việt thành một vector đặc trưng, còn trong mô hình AttentionOCR, thì dữ liệu đầu vào này là một ảnh.
Một ảnh qua mô hình CNN, sẽ cho một feature maps có kích thước channelxheightxwidth, feature maps này sẽ trở thành đầu vào cho mô hình LSTM, tuy nhiên, mô hình LSTM chỉ nhận chỉ nhận đầu vào có kích thước là hiddenxtime_step. Một cách đơn giản và hợp lý là 2 chiều cuối cùng heightxwidth của feature maps sẽ được duổi thẳng. Feature maps lúc này sẽ có kích thước phù hợp với yêu cầu của mô hình LSTM.
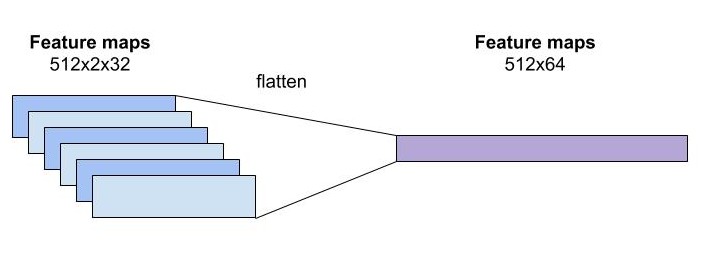
Feature maps của mô hình CNN sau khi được flatten thì được truyền vào làm input của mô hình LSTM, tại mỗi thời điểm, mô hình LSTM cần dự đoán từ tiếp theo trong ảnh là gì.
TransformerOCR
Các bạn có thể tận dụng kiến trúc transformer thay cho mô hình LSTM để dự đoán từ tiếp theo trong ảnh. Chi tiết kiến trúc và cách hoạt động của mô hình transformer mình đã giải thích rất chi tiết tại đây.
Huấn Luyện Mô Hình
Huấn luyện mô hình AttenionOCR hay TransformerOCR hoàn toàn giống với luyện mô hình seq2seq, chúng đều sử dụng cross-entropy loss để tối ưu thay vì sử dụng CTCLoss như mô hình CRNN, tức là tại mỗi thời điểm mô hình dự đoán một từ sau đó so sánh với nhãn để tính loss và cập nhật lại trọng số của mô hình.
Hạn Chế Của Mô Hình Sử dụng CTCLoss
Đối với mô hình CRNN sử dụng CTCloss để làm hàm mục tiêu, số lượng kí tự đối đa có thể dự đoán bằng với widthxheight của feature maps. Do đó, các bạn cần phải cẩn thận điều chỉnh kiến trúc mô hình để có thể dự đoán được số kí tự phù hợp với từng bộ dataset. Đối với mô hình AttentionOCR hoặc TransformerOCR, các bạn không gặp vấn đề này, làm cho các bạn có thể dễ dàng sử dụng lại pretrained model cho các loại dữ liệu khác nhau.
Ngoài ra, AttentionOCR hoặc TransformerOCR đều có kiến trúc của mô hình dịch này seq2seq, do đó các thủ thuật của mô hình này đều có thể ứng dụng cho mô hình của chúng ta.
Thư Viện VietOCR
Thư viện VietOCR được mình xây dựng với mục đích hỗ trợ các bạn có thể sử dụng để giải quyết các bài toán liên quan đến OCR trong công nghiệp. Thư viện cung cấp cả 2 kiến trúc AtentionOCR và TransformerOCR. Tuy kiến trúc TransformerOCR hoạt động khá tốt trong NLP, nhưng theo mình nhận xét thì độ chính không có sự cải thiện đáng kể so với AttentionOCR mà thời gian dự đoán lại chậm hơn khá nhiều.
Mình có cung cấp pretrained model được mình huấn luyện trên tập dữ liệu 10m ảnh để các bạn có thể sử dụng nhanh chóng trong các bài toán mới. Tuy nhiên, mình khuyến khích các bạn huấn luyện mô hình trên tập dữ liệu mới của bản thân nếu muốn sử dụng trong công nghiệp.
Để thử nghiệm nhanh chóng mô hình các bạn có thể tham khảo notebook tại đây
Ở phần tiếp theo, mình sẽ hướng dẫn các bạn cách tạo bộ dataset phù hợp với thư viện, sử dụng thư viện để huấn luyện trên dataset mới, thay đổi cách augmentate, dự đoán cho ảnh mới và một số lưu ý khi sử dụng thư viện.
Dataset
Để huấn luyện mô hình các bạn cần chuẩn bị dữ liệu ít nhất là khoảng 3k mẫu, trong các dự án thực tế thì nên sử dụng 20k mẫu trở lên. Cấu trúc thư mục chứa dữ liệu
.
├── img
│ ├── 00000.jpg
│ ├── 00001.jpg
├── train_annotation.txt # nhãn tập train
└── val_annotation.txt # nhãn tập test
Dữ liệu file nhãn theo định dạng sau
path_to_file_name[tab]nhãn
img/74086.jpg 429/BCT-ĐTĐL
img/04225.jpg Như trên;
img/97822.jpg V/v: Duyệt dự toán chi phí Ban QLDA nhiệt điện 1 năm 2012 và
Custom Augmentor
Mặc định, mô hình có sử dụng augmentation, tuy nhiên các bạn có thể cần augmentate theo cách khác nhau để đảm bảo tính biến dạng ảnh không quá lớn so với dữ liệu gốc. Do đó, thư viện cho phép các bạn tự định nghĩa augmentation như ví dụ dưới, và truyền vào lúc huấn luyện.
from vietocr.loader.aug import ImgAugTransform
from imgaug import augmenters as iaa
class MyAugmentor(ImgAugTransform):
def __init__(self):
self.aug = iaa.GaussianBlur(sigma=(0, 1.0))
Huấn Luyện
Để huấn luyện mô hình các bạn chỉ cần tạo được bộ dataset của mình, sau đó thay đổi các tham số quan trọng là có thể huấn luyện mô hình dễ dàng.
from vietocr.tool.config import Cfg
from vietocr.model.trainer import Trainer
# Các bạn có thể chọn vgg_transformer hoặc vgg_seq2seq
config = Cfg.load_config_from_name('vgg_transformer')
# Các bạn có thể thay đổi tập vocab của mình hoặc để mặc định vì tập vocab của mình đã tương đối đầy từ các kí tự rồi
# lưu ý rằng các kí tự không có trong tập vocab sẽ bị lỗi
#config['vocab'] = 'tập vocab'
dataset_params = {
'name':'hw', # tên dataset do bạn tự đặt
'data_root':'./data_line/', # thư mục chứa dữ liệu bao gồm ảnh và nhãn
'train_annotation':'train_line_annotation.txt', # ảnh và nhãn tập train
'valid_annotation':'test_line_annotation.txt' # ảnh và nhãn tập test
}
params = {
'print_every':200, # hiển thị loss mỗi 200 iteration
'valid_every':10000, # đánh giá độ chính xác mô hình mỗi 10000 iteraction
'iters':20000, # Huấn luyện 20000 lần
'export':'./weights/transformerocr.pth', # lưu model được huấn luyện tại này
'metrics': 10000 # sử dụng 10000 ảnh của tập test để đánh giá mô hình
}
# update custom config của các bạn
config['trainer'].update(params)
config['dataset'].update(dataset_params)
config['device'] = 'cuda:0' # device để huấn luyện mô hình, để sử dụng cpu huấn luyện thì thay bằng 'cpu'
# huấn luyện mô hình từ pretrained model của mình sẽ nhanh hội tụ và cho kết quả tốt hơn khi bạn chỉ có bộ dataset nhỏ
# để sử dụng custom augmentation, các bạn có thể sử dụng Trainer(config, pretrained=True, augmentor=MyAugmentor()) theo ví dụ trên.
trainer = Trainer(config, pretrained=True)
# sử dụng lệnh này để visualize tập train, bao gồm cả augmentation
trainer.visualize_dataset()
# bắt đầu huấn luyện
trainer.train()
# visualize kết quả dự đoán của mô hình
trainer.visualize_prediction()
# huấn luyện xong thì nhớ lưu lại config để dùng cho Predictor
trainer.config.save('config.yml')
Inference
Sau khi huấn luyện mô hình các bạn sử dụng config.yml và trọng số đã huấn luyện để dự đoán hoặc chỉ sử dụng pretrained model của mình.
from vietocr.tool.predictor import Predictor
from vietocr.tool.config import Cfg
# config = Cfg.load_config_from_file('config.yml') # sử dụng config của các bạn được export lúc train nếu đã thay đổi tham số
config = Cfg.load_config_from_name('vgg_transformer') # sử dụng config mặc định của mình
config['weights'] = './weights/transformerocr.pth' # đường dẫn đến trọng số đã huấn luyện hoặc comment để sử dụng pretrained model của mình
config['device'] = 'cuda:0' # device chạy 'cuda:0', 'cuda:1', 'cpu'
detector = Predictor(config)
img = './a.JPG'
img = Image.open(img)
# dự đoán
s = detector.predict(img, return_prob=False) # muốn trả về xác suất của câu dự đoán thì đổi return_prob=True
Kết Quả
Mình cung cấp 2 pretrained model được huấn luyện trên 10m ảnh với kết quả trong bảng sau.
| Backbone | Config | Precision full sequence | Time |
|---|---|---|---|
| VGG19-bn - Transformer | vgg_transformer | 0.8800 | 86ms @ 1080ti |
| VGG19-bn - Seq2Seq | vgg_seq2seq | 0.8701 | 12ms @ 1080ti |
Một Số Kết Quả Thực Nghiệm Của Mô Hình Hiện Tại
-
Một vấn đề mình thấy hiện tại là mô hình khá nhạy cảm với sự thay đổi nhỏ của ảnh đầu vào khi các bạn sử dụng pretrained model trên tập dữ liệu mới chưa được huấn luyện. Do đó mình khuyến nghị các bạn nên huấn luyện lại mô hình nếu muốn sử dụng thực tế.
-
Mình đã sử beamsearch khi phát sinh câu, tuy nhiên độ chính xác không cải thiện có thể vì khi nhận dạng câu thì nội dung câu đó đã thể hiện rất rõ ràng trong ảnh rồi không giống như khi dịch máy, một câu tiếng việt có thể được dịch thành nhiều câu tiếng anh khác nhau.
-
Mô hình transformer không mang lại cải tiến vượt bậc trong bài toán OCR theo mình nghĩ vì câu mình cần nhận dạng đã thể hiện rõ ràng trong ảnh. Do đó sử dụng language model quá tốt cũng không mang lại hiệu quả.
Mình nghĩ rằng bài toán nhận dạng OCR là một bài toán nhận dạng, tức là việc sử dụng language model (dùng để phát sinh câu) xịn xò có thể quá dư thừa, thay vào đó nên tập trung vào việc nhận dạng từng kí tự ??? Tuy nhiên việc nhận dạng từng kí tự đòi hỏi chi phí đánh nhãn quá lớn vì các bạn cần phải vẽ boundary box cho từng kí tự và các boundary box giữa 2 kí tự liên tiếp có thể bị đè lên nhau hoặc phân biệt không rõ ràng. Do đó, tùy vào trường hợp cụ thể mà các bạn có thể sử dụng phương pháp hơp lý. Ví dụ với chứng minh thư, các kí tự thường to rõ và ít nội dung các bạn có thể xem xét đánh boundary box cho từng kí tự, tuy nhiên với các loại văn bản có nhiều nội dung cần OCR các bạn có thể chọn nhận dạng theo từng dòng.
Mình hy vọng các chia sẻ trên và thư viện VietOCR sẽ giúp các bạn giải quyết nhanh các bài toán số hóa. Nếu các bạn có thắc mắc gì vui lòng comment phía dưới hoặc liên hệ mình tại pbcquoc@gmail.com