
Tìm Hiểu Mô Hình YOLO Cho Bài Toán Object Detection - Understanding YOLO
Giới thiệu
You only look once (YOLO) là một mô hình CNN để detect object mà một ưu điểm nổi trội là nhanh hơn nhiều so với những mô hình cũ. Thậm chí có thể chạy tốt trên những IOT device như raspberry pi. Trong phần này, mình sẽ giới thiêu chi tiết YOLO v1, về sau chúng ta còn có YOLO v2,v3, chạy nhanh hơn nhưng phức tạp hơn và khó cài đặt. Hiểu được YOLO v1 sẽ giúp các bạn dễ dàng cài đặt những phiên bản sau. Đồng thời, mình cũng cung cấp source code cùng với bộ dữ liệu mẫu gồm 25k ảnh để huấn luyện một mô hình YOLO đơn giản.
Đầu vào mô hình là một bức ảnh, đối với bài toán object detection, chúng ta không chỉ phải phân loại được object trên bức ảnh mà còn phải định vị được vị trí của đối tượng đó. Object Detection có khá nhiều ứng dụng, ví dụ như hệ thống theo dõi người dân của Trung Quốc, từ đó có thể giúp chính quyền xác định được tội phạm lẫn trốn ở đó hay không, hoặc hệ thống xe tự lái, cũng phải xác định được người đi đường ở đâu từ đó đưa ra quyết định di chuyển tiếp theo.

Có một số hướng tiếp cận để giải quyết vấn đề, đồng thời mỗi lần chạy tốn rất nhiều thời gian. Mình sẽ liệt kê ra để các bạn có thể nắm được ý tưởng để giải quyết bài toàn object detection.
- Chia ảnh thành nhiều box, mỗi box các bạn sẽ detect object trong box đó. Vị trí của object chính là tạo độ của box đó.
- Thay vì chia thành từng box, chúng ta sẽ sử dụng một thuật toán để lựa chọn những region ứng viên (ví dụ như là thuật toán Selective Search), các vùng ứng viên này các bạn có thể tưởng như là những vùng liên thông với nhau trên kênh màu RGB, sau đó với mỗi vùng ứng viên này, chúng ta dùng model để phân loại object. Chúng ta có một số mô hình xây dựng theo kiểu này như RCNN, Fast RCNN
Rất rõ ràng, nhược điểm của các phương pháp trên là tốn rất nhiều tài nguyên để tính toán cho mội vùng trên một bức ảnh,và do đó không thể chạy realtime trên các thiết bị yếu.
Chi tiết mô hình
Một trong nhưng ưu điểm mà YOLO đem lại đó là chỉ sử dụng thông tin toàn bộ bức ảnh một lần và dự đoán toàn bộ object box chứa các đối tượng, mô hình được xây dựng theo kiểu end-to-end nên được huấn luyện hoàn toàn bằng gradient descent. Sau đây, mình sẽ trình bày chi tiết về mô hình YOLO
Grid System
Ảnh được chia thành ma trận ô vuông 7x7, mỗi ô vuông bao gồm một tập các thông tin mà mô hình phải dữ đoán.
- Đối tượng duy nhất mà ô vuông đó chứa. Tâm của đối tượng cần xác định nằm trong ô vuông nào thì ô vuông đó chứa đối tượng đó. Ví dụ tâm của cô gái nằm trong ô vuông màu xanh, do đó mô hình phải dự đoán được nhãn của ô vuông đó là cô gái. Lưu ý, cho dù phần ảnh cô gái có nằm ở ô vuông khác mà tâm không thuộc ô vuông đó thì vẫn không tính là chứa cô gái, ngoài ra, nếu có nhiều tâm nằm trong một ô vuông thì chúng ta vẫn chỉ gán một nhãn cho ô vuông đó thôi. Chính ràng buột mỗi ô vuông chỉ chứa một đối tượng là nhược điểm của mô hình này. Nó làm cho ta không thể detect những object có tầm nằm cùng một ô vuông. Tuy nhiên chúng ta có thể tăng grid size từ 7x7 lên kích thước lớn hơn để có thể detect được nhiều object hơn. Ngoài ra, kích thước của ảnh đầu vào phải là bội số của grid size.

- Mỗi ô vuông chịu trách nhiệm dự đoán 2 boundary box của đối tượng. Mỗi boundary box dữ đoán có chứa object hay không và thông tin vị trí của boundary box gồm trung tâm boundary box của đối tượng và chiều dài, rộng của boundary box đó. Ví vụ ô vuông màu xanh cần dự đoán 2 boundary box chứa cô gái như hình minh họa ở dưới. Một điều cần lưu ý, lúc cài đặt chúng ta không dự đoán giá trị pixel mà cần phải chuẩn hóa kích thước ảnh về đoạn từ [0-1] và dự đoán độ lệch của tâm đối tượng đến box chứa đối tượng đó. Ví dụ, chúng ta thay vì dữ đoán vị trí pixel của điểm màu đỏ, thì cần dự đoán độ lệch a,b trong ô vuông chứa tâm object.

Tổng hợp lại, với mỗi ô vuông chúng ta cần dữ đoán các thông tin sau :
- Ô vuông có chứa đối tượng nào hay không?
- Dự đoán độ lệch 2 box chứa object so với ô vuông hiện tại
- Lớp của object đó
Như vậy với mỗi ô vuông chúng ta cần dữ đoán một vector có (nbox+4*nbox+nclass) chiều. Ví dụ, chúng ta cần dự đoán 2 box, và 3 lớp đối với mỗi ô vuông thì chúng sẽ có một ma trận 3 chiều 7x7x13 chứa toàn bộ thông tin cần thiết.

CNN for YOLO Object Detection
Chúng ta đã cần biết phải dự đoán những thông tin nào đối với mỗi ô vuông, điều quan trọng tiếp theo là xây dựng một mô hình CNN có cho ra ouput với shape phù hợp theo yêu cầu của chúng ta, tức là gridsize x gridsize x (nbox+4*nbox+nclass). Ví dụ với gridsize là 7x7 là mỗi ô vuông dự đoán 2 boxes, và có 3 loại object tất cả thì chúng ta phải cần output có shape 7x7x13 từ mô hình CNN
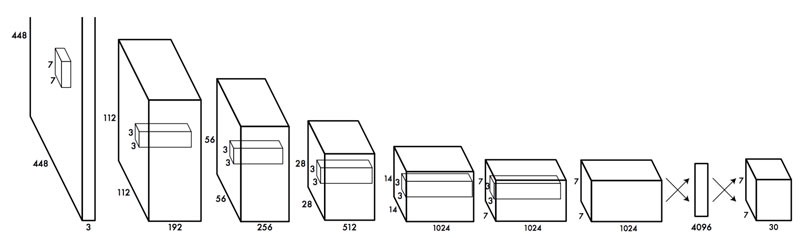
YOLO sử dụng linear regression để dự đoán các thông tin ở mỗi ô vuông. Do đó, ở layer cuối cùng chúng ta sẽ không sử dụng bất kì hàm kích hoạt nào cả. Với ảnh đầu vào là 448x448, mô hình CNN có 6 tầng max pooling với size 2x2 sẽ giảm 64 lần kích thước ảnh xuống còn 7x7 ở output đầu ra. Đồng thời thay vì sử dụng tầng full connected ở các tầng cuối cùng, chúng ta có thể thay thế bằng tầng 1x1 conv với 13 feature maps để output shape dễ dàng cho ra 7x7x13.
Loss function
Chúng ta đã định nghĩa được những thông tin mà mô hình cần phải dự đoán, và kiến trúc của mô hình CNN. Bây giờ là lúc mà chúng ta sẽ định nghĩa hàm lỗi.
YOLO sử dụng hàm độ lỗi bình phương giữ dự đoán và nhãn để tính độ lỗi cho mô hình. Cụ thể, độ lỗi tổng của chúng ta sẽ là tổng của 3 độ lỗi con sau:
- Độ lỗi của việc dữ đoán loại nhãn của object - Classifycation loss
- Độ lỗi của dự đoán tạo độ cũng như chiều dài, rộng của boundary box - Localization loss
- Độ lỗi của ô vuông có chứa object nào hay không - Confidence loss
Chúng ta mong muốn hàm lỗi có chức năng sau. Trong quá trình huấn luyện, mô hình sẽ nhìn vào những ô vuông có chứa object. Tăng classification score lớp đúng của object đó lên. Sau đó, cũng nhìn vào ô vuông đó, tìm boundary box tốt nhất trong 2 boxes được dự đoán. Tăng localization score của boundary box đó lên, thay đổi thông tin boundary box để gần đúng với nhãn. Đối với những ô vuông không chứa object, giảm confidence score và chúng ta sẽ không quan tâm đến classification score và localization score của những ô vuông này.
Tiếp theo, chúng ta sẽ đi lần lượt vào chi tiết ý nghĩa của các độ lỗi trên.
Classification Loss
Chúng ta chỉ tính classification loss cho những ô vuông được đánh nhãn là có object. Classification loss tại những ô vuông đó được tính bằng đỗ lỗi bình phương giữa nhãn được dự đoán và nhãn đúng của nó.
Trong đó:
: bằng 1 nếu ô vuông đang xét có object ngược lại bằng 0
: là xác xuất có điều của lớp c tại ô vuông tương ứng mà mô hình dự đoán
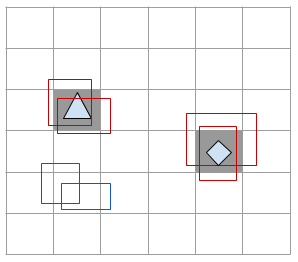
Ví dụ, trong hình minh họa ở trên, chúng ta có 2 object tại ô vuông (dòng,cột) là (2,1) và (3,4), chứa object là hình tam giác và hình tức giác đều. Độ lỗi classification loss chỉ tính cho 2 object này mà ko quan tâm đến những ô vuông khác. Lúc cài đặt chúng ta cần lưu ý phải nhân với một mask để triệt tiêu giá trị lỗi tại những ô vuông ko quan tâm.
Localization Loss
Localization loss dùng để tính giá trị lỗi cho boundary box được dự đoán bao gồm offset x,y và chiều dài, rộng so với nhãn chính xác của chúng ta. Các bạn nên lưu ý rằng, chúng ta không tính toán trực tiếp giá trị lỗi này trên kích thước của ảnh mà cần chuẩn dưới kính thước ảnh về đoạn [0-1] đối với tọa độ điểm tâm, và không dữ đoán trực tiếp điểm tâm mà phải dự đoán giá trị lệch offset x,y so với ô vuông tương ứng. Việc chuẩn hóa kích thước ảnh và dự đoán offset làm cho mô hình nhanh hội tụ hơn so với việc dự đoán giá trị mặc định.
Độ lỗi localization loss được tính bằng tổng đỗ lỗi bình phương của offsetx, offsety và chiều dài, rộng trên tất cả các ô vuông có chứa object. Tại mỗi ô vuông đúng,ta chọn 1 boundary box có IOU (Intersect over union) tốt nhất, rồi sau đó tính độ lỗi theo các boundary box này. Theo hình mình họa trên chúng ta có 4 boundary box tại ô vuông đúng có viền màu đỏ, chúng ta chọn 1 box tại mỗi ô vuông để tính độ lỗi. Còn box xanh được bỏ qua.
Localization loss là độ lỗi quan trọng nhất trong 3 loại độ lỗi trên. Do đó, ta cần đặt trọng số cao hơn cho độ lỗi này.
Confidence Loss
Confidence loss thể hiện độ lỗi giữa dự đoán boundary box đó chứa object so với nhãn thực tế tại ô vuông đó. Độ lỗi này tính nên cả những ô vuông chứa object và không chứa object.
Độ lỗi này là độ lỗi bình phường của dự đoán boundary đó chứa object với nhãn thực tế của ô vuông tại vị trí tương ứng, chúng ta lưu ý rằng, độ lỗi tại ô vuông mà nhãn chứa object quan trọng hơn là độ lỗi tại ô vuông không chứa object, do đó chúng ta cần sử dụng hệ số lambda để cân bằng điều này.
Tổng kết lại, tổng lỗi của chúng ta sẽ bằng tổng của 3 loại độ lỗi trên
Dự đoán lớp và tạo độ boundary box sau quá trình huấn luyện - Inference
Chúng ta chỉ giữ lại những boundary box mà có chứa object nào đó. Để làm điều này, chúng ta cần tính tích của xác xuất có điều kiện ô vuông thuộc về lớp i nhân với sác xuất ô vuông đó chứa object, chỉ giữ lại những boundary box có giá trị này lớn hơn ngưỡng nhất định.
Mỗi object lại có thế có nhiều boundary box khác nhau do mô hình dự đoán. Để tìm boundary box tốt nhất các object, chúng ta có thể dùng thuật toán non-maximal suppression để loại những boundary box giao nhau nhiều, tức là có IOU giữ 2 boundary box lớn.
Để tính IOU giữ 2 box chúng ta cần tính diện tích giao nhau giữa 2 box chia cho tổng diện tích của 2 box đó.

Cài đặt thuật toán
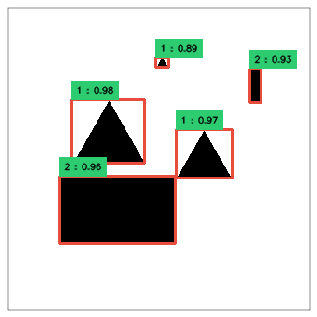
Mình thực hiện cài đặt YOLO v1 trên tập dữ liệu mẫu gồm 25k ảnh được phát sinh. Kết quả mô hình dự đoán khá chính xác các object trong ảnh với lớp chính xác.
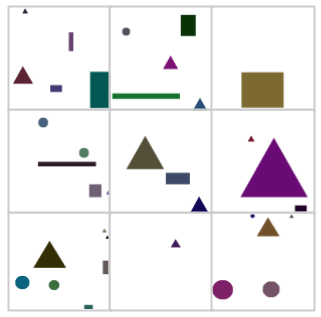
Các bạn có thể tham khảo file hướng dẫn cài đặt thuật toán tại đây. Mình có hướng dẫn chi tiết từng bước từ cách tạo bộ dữ liệu đến quá trình cài đặt CNN, cũng như tính hàm loss và hiển thị kết quả. Các bạn có thể dùng kết quả này để tham khảo và mở rộng cho những tập dữ liệu khác.
Link download dataset cho những bạn nào cần tại đây