
Tìm Hiểu và Áp Dụng Cơ Chế Attention - Understanding Attention Mechanism
Giới thiệu
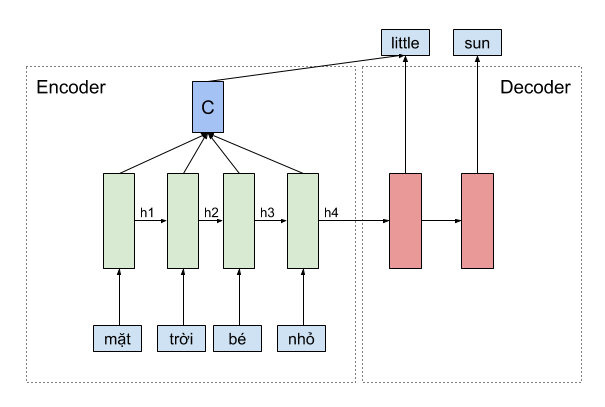
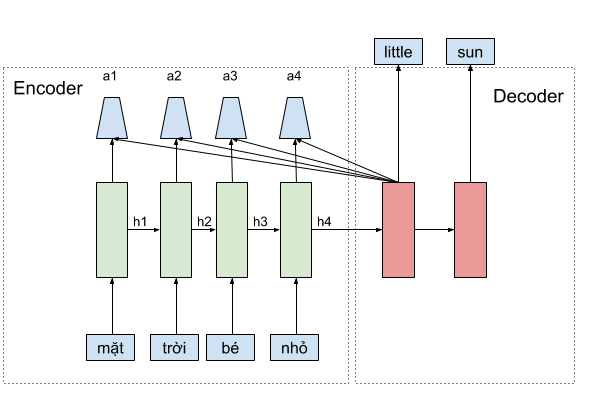
Theo thông lệ mình sẽ giới thiệu sơ qua cơ chế attention là gì, lịch sử, những cột mốc từ khi attention được ứng dụng. Tuy nhiên, do mình thấy rằng một số bạn nghĩ rằng cơ chế attention khá phức tạp nên trước hết mình muốn nhấn mạnh rằng: Cơ chế attention chỉ đơn giản là trung bình có trọng số của những “thứ” mà chúng ta nghĩ nó cần thiết cho bài toán, điều đặc biệt là trọng số này do mô hình tự học được. Cụ thể, trong bài toán dịch máy ở ví dụ dưới, khi sử dụng cơ chế attention để phát sinh từ little, mình sẽ cần tính một vector context C là trung bình có trọng số của vector biểu diễn các từ mặt, trời, bé, nhỏ tương ứng với vector \(h_{1}, h_{2}, h_{3}, h_{4}\) rồi sử dụng thêm vector context \(c\) này tại lúc dự đoán từ little, và nhớ rằng, trọng số này là các số scalar, được mô hình tự học. Các bạn đã thấy cơ chế attention thật đơn giản rồi nhỉ. Vậy chúng ta hãy bắt đầu đi vào chi tiết.
Tổng quan
Theo thực tế, mình nghĩ bộ não của chúng ta cũng có cơ chế attention của riêng nó. Ví dụ như, mắt của chúng ta có tầm nhìn 120 độ theo cả chiều thẳng đứng và ngang. Tuy nhiên, tại một thời điểm, hầu như chúng ta chỉ xử lý một phần nhỏ thông tin của bức ảnh. Bạn có để ý khi chúng ta lái xe, lúc rẽ trái, hay phải, chúng ta chỉ chú ý vào một phần không gian trên kính chiếu hậu mà thôi, rồi từ đó mới xử lý để đưa ra quyết định di chuyển tiếp theo. Cơ chế này của bộ não giúp chúng ta không cần nhiều năng lượng để đưa ra quyết định tuy nhiên vẫn cho kết quả tin cậy.
Có khá nhiều loại cơ chế attention khác nhau, tuy nhiên tổng quan chúng ta có 2 loại:
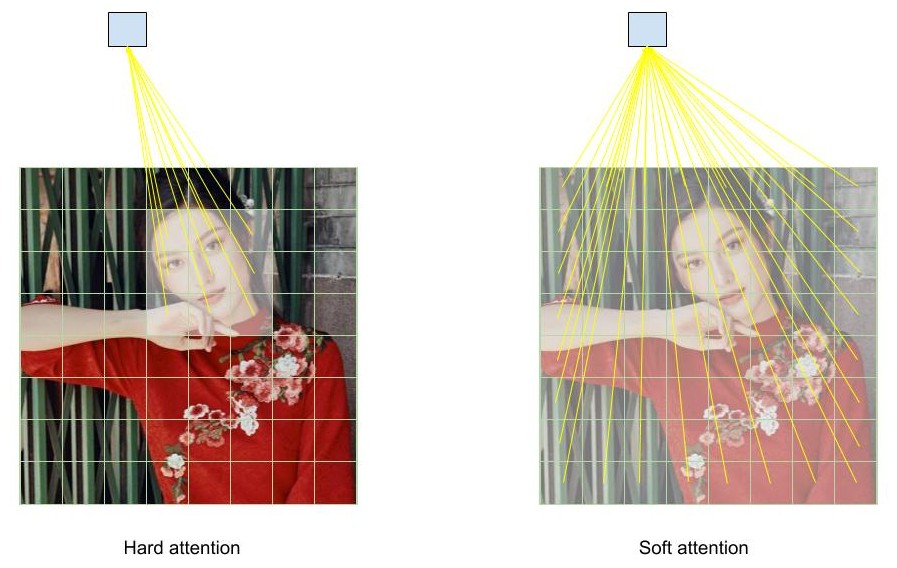
- Hard Attention: sử dụng reinforcement learning để học vị trí cần phải chú ý
- Soft Attention: học bộ trọng số bằng thuật toán backpropagation
Với hard attention, mô hình sẽ chọn ngẫu nhiên một vùng ảnh để chú ý, do mình không có nhãn vùng nào cần được chú ý, nên cũng không tính được gradient lúc này. Để giải quyết vấn đề này, mình sẽ áp dụng reinforcement learning. Cụ thể như thế nào mình sẽ không đề cập vì đó không phải là vấn đề mình muốn giới thiệu đến các bạn, và do sử dụng reinforcement learning nên cũng gặp những khó khăn của phương pháp này như khó hội tụ, mà kết quả thật ra cũng không tốt hơn so với soft attention. Tuy nhiên, cũng có ưu điểm như là vì chỉ chọn một vùng ảnh để tính toán nên sẽ giảm được tài nguyên máy tính cần để xử lý.
Với soft attention, cũng là phần thú vị mà mình muốn giới thiệu đến các bạn. Mô hình sẽ học trọng số để chú ý trên tất cả các phần thông tin của bức ảnh, câu, hoặc bất cứ thứ gì mà mình nghĩ rằng việc tổng hợp thông tin của tất cả các phần là cần thiết để đưa ra dự đoán. Tổng hợp thông tin này được tính bằng trung bình cộng có trọng số của tất cả các phần thông tin. Những trọng số này được mô hình tự học dễ dàng bằng backpropagation. Vì dễ tối ưu và không phức tạp trong lúc cài đặt nên soft attention, được cộng đồng tập trung phát triển rất nhiều nên có khá nhiều phiên bản cải tiến khác nhau. Nhưng mà ý tưởng cũng tương đối giống nhau, nên chỉ cần hiểu được cơ bản trong bài này thì các bạn đã có thể đọc những phiên bản khác dễ dàng.
Mình liệt kê ra một số phiên bản khác nhau của soft attention để các bạn có thể nắm được một số ý tưởng chính
- Learn to align trong bài toán dịch máy của Bahdanau có thể xem như là phiên bản đầu tiên được mọi người chú ý, sử dụng soft attention để học cách tổng hợp thông tin từ câu được dịch để phát sinh câu đích. Trong bài này, mình sẽ lấy công thức được ghi trong bài báo này để diễn giải lại cho các bạn.
- Global vs Local attention của anh Lương Minh Thắng. Global attention thì khá giống như của Bahdanau, còn local attention thì lấy ý tưởng từ hard attention, tức là học thêm vị trí cần được chú ý. Các bạn muốn tìm hiểu thì đọc paper nhé.
- Self Attention cho phép học mối tương quan giữ thông tin của từ hiện tại với những từ trước đó. Từ Self là ám chỉ bản thân của từ đó. Nhờ việc áp dụng cơ chế self attetion, tác giả của bài báo Attention is All you Need đã đề xuất mô hình Transformer, cho phép thay thế bỏ hoàn toàn kiến trúc recurrent của mô hình RNN bằng các mô hình full connected. Đây là một cột mốc khá quan trọng trong việc áp dụng cơ chế self attention cho các bài toàn NLP.
Chi tiết cơ chế Attention
Trong phần này, mình trình bày chi tiết cơ chế attention, hầu hết các phiên bản cải tiền điều có dựa trên những ý tưởng của những công thức này. Để trình bày, mình sẽ lấy ngữ cảnh trong bài toán dịch máy, sau đó, nêu ra những hạn chế, và cách khắc phục bằng cơ chế attention.
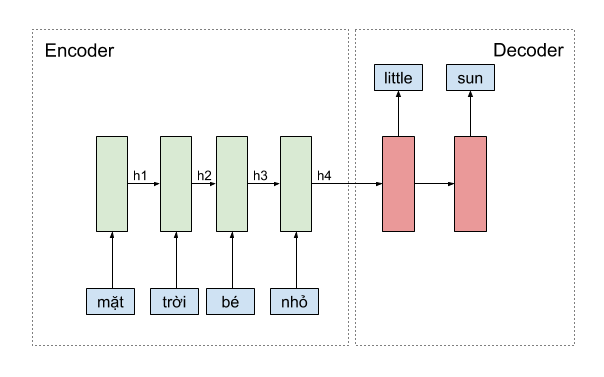
Trong bài toán dịch máy, chúng ta thường hay sử dụng mô hình như ở hình minh họa phía dưới. Mô hình encoder phải nén tất cả thông tin của một câu lại thành một vector biểu diễn duy nhất, chứa toàn bộ thông tin cần thiết để mô hình decoder có thể dịch thành câu đích. Vấn đề nằm ở chỗ, những câu dài sẽ không được dịch chính xác vì thông tin không được lưu trữ đủ trong một vector biểu diễn duy nhất.
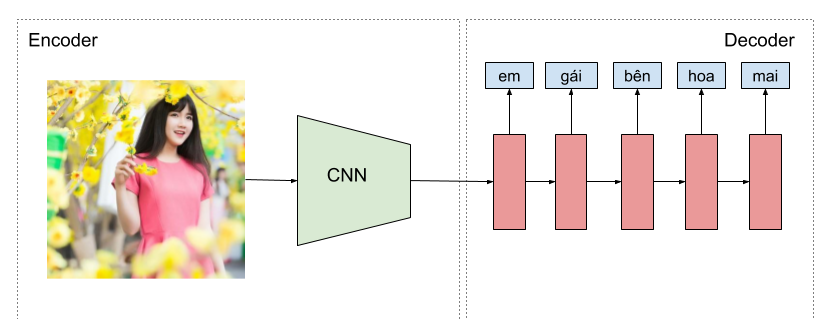
Cũng tương tự như trong bài toán phát sinh mô tả ảnh. Mô hình CNN cần lưu trữ thông tin toàn bộ bức ảnh lại thành một vector duy nhất, rồi sau đó mô hình encoder sẽ phát sinh câu mô tả dựa theo thông tin lưu trong vector này, tuy nhiên, vector này có thể không chứa đủ thông tin để phát sinh cho toàn bộ câu mô tả.
Để giải quyết vấn đề này, chúng ta sẽ sử dụng cơ chế attention, cho phép mô hình có thể chú ý vào từng phần của câu hoặc bức ảnh một cách rõ ràng. Từ đó,thông tin không cần phải nén vào một vector biểu diễn duy nhất. Ngoài ra, cơ chế attention cho phép mình có thể hiểu được những từ hay phần ảnh nào quyết định đến kết quả hiện tại.
Đầu tiên ta cần tính vector context chứa thông tin cho từ hiện tại bằng cách tính trung bình có trọng số như sau
Ví dụ tại thời điểm dự đoán từ little thì \(c\) chính là context vector được tổng hợp tại thời điểm đó bằng cách tính trung bình có trọng số của \(h_{1}, h_{2}, h_{3}, h_{4}\), tương tự chúng ta cũng tính context vector tại những thời điểm khác với trọng số \(\alpha\) khác, được tính riêng cho thời điểm đó. Vậy \(\alpha\) được tính như thế nào ? Rõ rằng, các bạn có thể suy luận được rằng, \(\alpha\) phụ thuộc vào các thông tin từ các \(h\), và cũng từ chính thông tin hiện tại của mô hình decoder.
Trong đó: \(a\) là mô hình học hệ số \(\alpha\) tại mỗi thời điểm. Mô hình này đơn giản có thể là một tầng full connected chuyển từ n chiều thành 1 chiều. Lưu ý rằng, trọng số cần học của mô hình \(a\) cũng chia sẻ theo thời gian như mô hình RNN.
Sau cùng, các bạn cần phải chuẩn hóa tổng hệ số \(\alpha\) lại bằng 1 bằng cách sử dụng hàm softmax
Cuối cùng, chúng ta sử dụng thêm vector context trong quá trình dự đoán.
Áp dụng
Trong phần này, mình chia sẻ một vài ý tưởng sử dụng cơ chế attention trong các bài toán mà mình đã gặp, trong hầu hết các trường hợp đều cho kết quả tốt hơn khi áp dụng cơ chế này. Bên cạnh đó, một trong những điều mà mình rất thích ở cơ chế này là có thể hiểu được quá trình dự đoán phụ thuộc vào phần thông tin nào của bức ảnh hay từ nào.
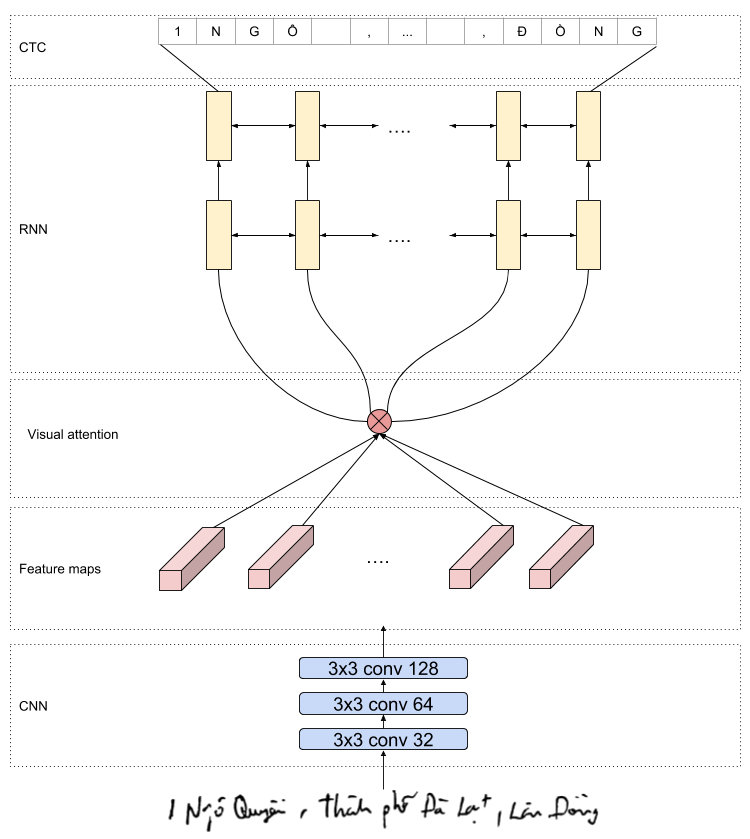
Trong mô hình nhận dạng chữ Tiếng Việt
Như mình có chia sẻ ở một bài blog nhận dạng tiếng việt, các bạn có thể hoàn toàn áp dụng cơ chế attention để cải thiện kết quả dự đoán của mô hình. Ở bài toán nhận dạng chữ Tiếng Việt, các bạn sử dụng mô hình CNN để học một vector biểu diễn 2 chiều duy nhất, rồi sau đó sử dụng mô hình LSTM để decoder thành các chữ tiếng việt. Hạn chế của hướng tiếp cận naỳ cũng giống như những vấn đề đã nêu ở trên, đó là thông tin phải nén thành một vector duy nhất mà tại mỗi thời điểm phát sinh chúng ta không cần tất cả thông tin này. Do đó, để giải quyết vấn đề này, các bạn có sử dụng một tầng attention giữ mô hình CNN với điều kiện đầu ra của mô hình CNN là các feature map trên từng phần ảnh. Sử dụng cơ chế attention cũng là một trong những chiến lượt giúp nhóm mình đã đạt được top 1 trong cuộc thi do Cinnamon tổ chức.
Trong mô hình phân tích ngữ nghĩa - sentiment analysis
Chúng ta có thể áp dụng cơ chế attention trong phân tích ngữ nghĩa của một câu. Cơ chế này cho mình thấy được những keywords nào quan trọng trong kết quả dự đoán của một câu, và theo mình thấy, các bạn có thể cải thiện được kết quả dự đoán một cách đáng kể.
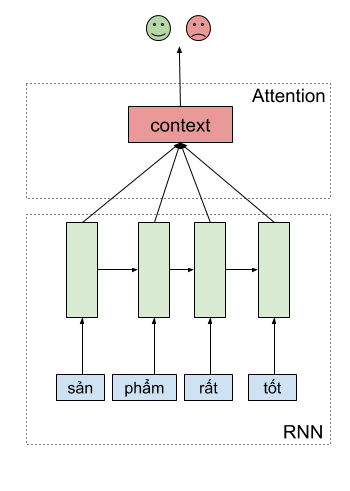
Thay vì dùng hidden state ở thời điểm cuối cùng để phân tích ngữ nghĩa của câu, chúng ta có thể tổng hợp thông tin từ các hidden states ở thời điểm khác thông qua cơ chế attention, rồi dùng vector này để thực hiện phân tích ngữ nghĩa của câu.
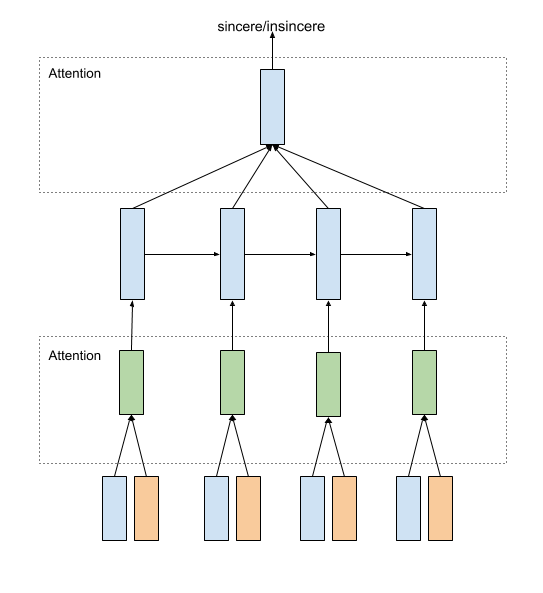
Attention cho nhiều vector embedding - Quora Insincere Questions Classification
Khi tham gia vào cuộc thi Quora Insincere Questions Classification team mình đã sử dụng attention cho tầng embedding. Ở bài toán này, các bạn phải phân loại các câu hỏi trên quora có phải là hợp lệ hay không?. Các đội tham gia chỉ được sử dụng một số loại embedding vectors cho sẵn như là glove, paragram, google news. Một số đội lựa chọn concat cả 3 loại vector, hoặc lấy trung bình cộng, hoặc huấn luyện các mô hình riêng biệt trên từng embedding. Team mình đã lựa chọn sử dụng tầng attention cho các loại embedding trên (và rất nhiều tuning khác) từ đó giúp đạt được Gold Medal trong cuộc thi này. Các bạn có thể tham khảo kiến trúc dưới đây mà team mình đã áp dụng
Và Gold Medal xứng đáng cho sự cố gắng của cả team.

Cài đặt thuật toán
Để minh họa cho cơ chế attention, mình đã cài đặt cơ chế này trong bài toán seq2seq được đơn giản hóa. Đồng thời mình cũng minh họa kết quả tại mỗi thời điểm phụ thuộc vào từ nào trong câu đầu vào.
Code các bạn có thể tìm tại đây nhé. Trong code mình có comment chi tiết từng bước, hy vọng các bạn có thể đọc hiểu các thực hiện từng bước như thế nào.
Dataset
Để minh họa cơ chế attention, mình sử dụng tập dataset tự phát sinh, với đầu vào là các câu biểu diễn ngày tháng năm của con người đọc, và nhãn là ngày tháng năm tương ứng do máy tính hiểu.
| Input | Label |
|---|---|
| 12, thg 9 2010 | 2010-09-12 |
| Thứ Tư, ngày 21 tháng 3 năm 1973 | 1973-03-21 |
| 31 thg 7, 1988 | 1988-07-31 |
Mình đã phát sinh tổng cộng 20k mẫu, trong đó 5k dùng để validation.
Kết quả
Vì tập dữ liệu mình dùng để minh họa khá đơn giản, nên chỉ cần sau 3 epochs bạn đã có kết quả tương đối chính xác. Mình huấn luyện đến 10 epochs thì loss là 0.023 trên tập validation.
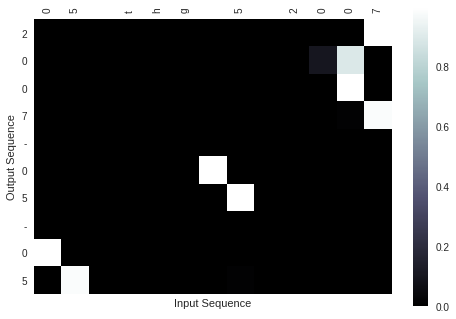
Dưới này là một minh họa của câu đầu vào là “05 thg 5 2017”, các bạn có thể thấy rằng các phần ngày tháng năm khi phát sinh đều được mô hình chú ý một cách đúng lúc và chính xác.
Kết luận
Các bạn có thể thấy cơ chế attention thật đơn giản rồi nhỉ. Vậy các áp dụng vào những vấn đề bạn gặp phải. Các bạn có thể chia sẻ những thú vị trong việc áp dụng cơ chế nào đến mình tại pbcquoc@gmail.com nhé.